Luku 6 Epäparametrisia tilastollisia menetelmiä lineaariselle regressiolle
Luvussa 3.5 käsittelimme tilastollisia testejä liittyen lineaariseen regressiomalliin \[\begin{equation} \tag{6.1} y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \ldots + \beta_d x_{id} + \varepsilon_i, \quad i\in\{1, \ldots, n\}. \end{equation}\] Käsitellyt testit olivat parametrisia, koska testeissä oletimme satunaisvirheiden noudattavan normaalijakaumaa (katso määritelmä 3.1 valkoiselle kohinalle).
Kuitenkin usein on kohtuutonta olettaa, että satunnaistermit \(\varepsilon_i\) noudattavat jotain tiettyä parametrista jakaumaa kuten normaalijakaumaa. Tämän vuoksi tässä luvussa esittelemme epäparametrisia menetelmiä lineaarisen regression kontekstissa. Luvussa 6.1 annamme epäparametriset vastineet luvun 3.5 tilastollisille testeille. Luvussa 6.2 esittelemme epäparametrisen menetelmän luottamusvälien muodostamiseen parametreille \(\beta_j\).
Kaikissa tämän luvun menetelmissä oletamme, että virhetermit ovat määritelmän 6.1 mukaista valkoista kohinaa. Ero määritelmien 3.1 ja 6.1 välillä on, että nyt emme oleta virhetermeille mitään tiettyä jakaumaa.
Määritelmä 6.1 (Valkoinen kohina, joustavampi määritelmä) Mallin (6.1) virheet \(\varepsilon_i\) ovat satunnaismuuttujia, joille pätee seuraavat oletukset.
Satunnaisvirheet \(\varepsilon_i\) ovat riippumattomia ja samoin jakautuneita.
Kaikkien satunnaisvirheiden \(\varepsilon_i\) odotusarvo on nolla ja varianssi ei riipu indeksistä \(i\) eli \[\begin{equation*} \mathbb{E}(\varepsilon_i) = 0 \quad\text{ja}\quad \mathrm{Var}(\varepsilon_i) = \sigma^2 > 0 \quad\text{kaikille}\quad i\in\{1,\ldots, n\}. \end{equation*}\]
6.1 Permutaatiotesti
Ensin esittelemme epäparametrisen vastineen lineaarisen mallin merkitsevyyden testaamiseen (parametrinen testi olisi F-testi). Tämän jälkeen esittelemme epäparametrisen vastineen yhden kertoimen \(\beta_j\), \(j\in\{1, \ldots, d\}\), merkitsevyyden testaamiseen (parametrinen testi olisi t-testi).
Luvun molempien testien ideat ovat hyvin samankaltaisia – testeissä dataa “sekoitetaan” eli permutoidaan jollain tavalla. Tämän vuoksi näitä tilastollisia testejä kutsutaan permutaatiotesteiksi.
6.1.1 Mallin merkitsevyys
F-testin testisuure kaavassa (3.13) lasketaan selitysasteen \(R^2\) (joka aina välillä \([0,1]\)) avulla. Muista, että \(R^2\) kuvaa sitä, kuinka suuren osan selitettävän muuttujan \(y\) vaihtelusta sovitettu malli selittää. Jos \(R^2\approx 1,\) niin malli selittää suuren osan selitettävän muuttujan vaihtelusta. Jos \(R^2\approx 0\), niin satunnaisvirhe selittää suurimman osan selitettävän muuttujan vaihtelusta.
Myös epäparametrinen testi mallin merkitsevyydelle voidaan rakentaa selitysasteen avulla. Ideana on tutkia, onko \(R^2\) arvo tietynlainen (esimerkiksi \(0.2\), \(0.001\) tai \(0.5\)) vain sattumalta vai kuvaako \(R^2\) arvo sitä, että malli on oleellinen selitettävän ilmiön kannalta. Voisi siis ajatella, että jos “satunnaisella” datalla saamme samaa suuruusluokkaa olevan \(R^2\) arvon kuin alkuperäisellä datalla, niin malli ei ole merkitsevä. Permutaatiotesti (eng: permutation test) perustuu juuri tähän ideaan. Permutaatiotestissä testaamme seuraavaa nollahypoteesia \(H_0\) vaihtoehtoista hypoteesia \(H_1\) vastaan \[\begin{equation*} \begin{split} &H_0: \beta_1 = \beta_2 = \cdots = \beta_d = 0, \\ &H_1: \beta_j \neq 0 \quad\text{jollekin}\quad j\in\{1, \ldots, d\}. \end{split} \end{equation*}\] Nämä ovat siis täysin samat hypoteesit kuin F-testissä. Permutaatiotesti mallin merkitsevyydelle merkitsevyystasolla \(\alpha\) (esimerkiksi \(\alpha = 0.05\)) suoritetaan seuraavasti.
Olkoon \[\begin{equation*} \left\{\underbrace{(y_1, x_{11}, x_{12}, \ldots, x_{1d})}_{\text{$(d+1)$-ulotteinen havainto nro $1$}}, \ldots, \underbrace{(y_n, x_{n1}, x_{n2}, \ldots, x_{nd})}_{\text{$(d+1)$-ulotteinen havainto nro $n$}}\right\} \end{equation*}\] alkuperäinen otos, jonka otoskoko on \(n\). Kirjoitetaan havainto \(i\) muodossa \((y_i, x_{i1}, x_{i2}, \ldots, x_{id}) = (y_i, \boldsymbol x_i)\), jossa \(\boldsymbol x_i\in\mathbb{R}^d\). Laske selitysaste \(R^2\) alkuperäisestä otoksesta \(\left\{(y_1, \boldsymbol x_1), \ldots, (y_n, \boldsymbol x_n)\right\}\).
Olkoon \(i,\ell\in\{1, \ldots, n\}\). Muodosta uusi \(n\) kokoinen otos, joka koostuu uusista pareista \((y_i, \boldsymbol x_{\ell})\), joissa mahdollisesti \(\ell\neq i\). Muodosta parit niin, että jokainen alkuperäisen otoksen \(y_i\) ja \(x_\ell\) käytetään tasan kerran.
Askeleen 2 mukaisia permutoituja otoksia on mahdollista muodostaa \(n!\) kappaletta. Muodosta siis kaikki mahdolliset permutoidut otokset.
Laske selitysaste \(R_k^2\) jokaiselle \(k = 1, \ldots, n!\) permutoidulle otokselle.
Järjestä arvot \(R_1^2, \ldots, R_{n!}\) suuruusjärjestykseen. Laske \(\left[(1 - \alpha)\times m\right]\) järjestetty selitysaste. Tässä notaatio \([\cdot]\) tarkoittaa pyöristämistä lähimpään kokonaislukuun. Tarkoitus on siis laskea selitysasteita \(\left\{R_1^2, \ldots, R_{n!}^2\right\}\) vastaava \((1 - \alpha)\)-otoskvantiili. Jos alkuperäisestä otoksesta laskettu \(R^2\) on suurempi kuin laskettu otoskvantiili, niin nollahypoteesi \(H_0\) hylätään.
Huomautus 6.1 Yllä kuvatussa permutaatiotestin algoritmissa muodostamme \(n!\) otosta askeleessa 2. Tämä voi olla kuitenkin laskennallisesti liian vaativaa jopa suhteellisen pienille otoksille. Esimerkiksi jos otoskoko on \(n = 10\), niin meidän täytyisi muodostaa \(n! = 10 \cdot 9 \cdot \ldots \cdot 2\cdot 1 \approx 3.6 \cdot 10^6\) permutoitua otosta. Usein tapana on siis suorittaa permutaatiotesti satunnaisesti valituilla otoksilla, kun otoksia valitaan esimerkiksi \(m = 1000\) kappaletta. Tällöin permutaatiotestin tuloksiin liittyy pientä satunnaisuutta riippuen siitä, mitkä permutoidut otokset valitaan. Pidä tämä mielessä kun pääset tutkimaan esimerkkiin 6.2 liittyviä kuvia 6.1 ja 6.2).
Alla sovellamme permutaatiotestiä mallin merkitsevyydelle käytännössä.
Esimerkki 6.1 (Permutaatiotesti ja mallin merkitsevyys) Käytämme samaa dataa kuin esimerkissä 3.3. Eli meillä on kuvitteellinen \(n = 10\) kokoinen havaintoaineisto. Havainnot ovat toteumia satunnaisvektorista \((Y, X_1, X_2)\), jossa
\(Y = \text{voitto kuukaudessa tuhansina euroina}\) (
profit),\(X_1 = \text{mainosbudjetti kuukaudessa tuhansina euroina}\) (
advertisement) ja\(X_2 = \text{tuotteen hinta tuhansina euroina}\) (
price).
## # A tibble: 10 × 3
## profit advertisement price
## <dbl> <dbl> <dbl>
## 1 -15.2 2.88 4.78
## 2 4.97 7.88 2.27
## 3 -8.51 4.09 3.39
## 4 2.64 8.83 2.86
## 5 13.8 9.40 0.515
## 6 -16.2 0.456 4.50
## 7 5.91 5.28 1.23
## 8 8.85 8.92 0.210
## 9 4.98 5.51 1.64
## 10 -18.5 4.57 4.77Tavoitteenamme on testata lineaarisen regressiomallin
\[\begin{equation*}
\texttt{profit}_i = \beta_0 + \beta_1 \texttt{advertisement}_i + \beta_2 \texttt{price}_i + \varepsilon_i
\end{equation*}\]
merkitsevyyttä permutaatiotestillä. Asetamme merkitsevyystasoksi \(\alpha = 0.05\). Ennen kuin kirjoitamme permutaatiotestin algoritmin kokonaisuudessaan, kuvailemme tarkemmin muutamaa tärkeää askelta. Alkuperäisestä otoksesta laskettu selitysaste \(R^2\) saadaan napattua funktion summary() tuottamasta muuttujasta.
# Fit model and compute summary
sale_lm_summary <- summary(lm(profit ~ advertisement + price, data = sale))
# Inspect how to pick R^2
names(sale_lm_summary)## [1] "call" "terms" "residuals" "coefficients"
## [5] "aliased" "sigma" "df" "r.squared"
## [9] "adj.r.squared" "fstatistic" "cov.unscaled"## [1] 0.94611Seuraavaksi näytämme, miten yksi permutoitu otos muodostetaan. Permutoidun otoksen voi muodostaa valitsemalla selittävektoreiden arvoja alkuperäisestä taulukosta käyttämällä funktiota sample(). On erittäin tärkeää, että funktiossa sample() asetat replace = FALSE. Tällöin on mahdollista valita sama arvo \(\boldsymbol x_i\) vain kerran.
n <- nrow(sale)
# Permutate observations of the explanatory variables
perm_sample_x <- sale[sample(1:n, n, replace = FALSE), -1]
# Combine original y and permutated x
perm_sample <- dplyr::bind_cols(sale[, 1], perm_sample_x)
perm_sample## # A tibble: 10 × 3
## profit advertisement price
## <dbl> <dbl> <dbl>
## 1 -15.2 4.09 3.39
## 2 4.97 4.57 4.77
## 3 -8.51 7.88 2.27
## 4 2.64 8.92 0.210
## 5 13.8 0.456 4.50
## 6 -16.2 5.51 1.64
## 7 5.91 2.88 4.78
## 8 8.85 5.28 1.23
## 9 4.98 9.40 0.515
## 10 -18.5 8.83 2.86Taulukoissa sale ja perm_sample selitettävää muuttujaa vastaava sarake (eli profit) on sama. Kuitenkin taulukossa perm_sample vektorit \((\texttt{advertisement}_i, \texttt{price}_i)\) ovat vaihtaneet paikkoja. Esimerkiksi taulukossa sale,
\[\begin{equation*}
(2.88, 4.78) = (\texttt{advertisement}_1, \texttt{price}_1)
\end{equation*}\]
mutta taulukossa perm_sample
\[\begin{equation*}
(2.88, 4.78) = (\texttt{advertisement}_7, \texttt{price}_7).
\end{equation*}\]
Permutoidusta otoksesta saadaan laskettua selitysaste \(R_k^2\) samaan tyyliin kuin alkuperäisestä otoksesta.
Nyt olemme valmiita kirjoittamaan permutaatiotestin algoritmin askeleet 1–4. Selkeyden vuoksi toteutamme algoritmin for silmukan avulla.
# Number of permutation samples
m <- 1000
# Sample size
n <- nrow(sale)
# Create a vector for storing R^2
rsq_perm <- rep(NA, m)
# Compute R^2 from the original sample
sale_lm_summary <- summary(lm(profit ~ advertisement + price, data = sale))
rsq_original <- sale_lm_summary$r.squared
for (i in 1:m) {
# Construct the ith permuted sample
perm_sample_x <- sale[sample(1:n, n, replace = FALSE), -1]
# Combine original y and permuted x
perm_sample <- dplyr::bind_cols(sale[, 1], perm_sample_x)
# Compute R^2 from the permuted sample
perm_lm_summary <- summary(lm(profit ~ advertisement + price,
data = perm_sample))
rsq_perm[i] <- perm_lm_summary$r.squared
}Vektori rsq_perm sisältää nyt permutoituja otoksia vastaavat selitysasteet \(R_1^2, \ldots, R_m^2\).
## [1] 0.5041981 0.3918123 0.2948301 0.1517311 0.1532220 0.1051823Jäljellä on vielä algoritmin askel 5. Haluamme siis laskea \((1-\alpha)\)-otoskvantiilin selitysasteista \(\left\{R_1^2, \ldots, R_m^2\right\}\), kun \(\alpha = 0.05\). Tämän voi helposti suorittaa funktiolla quantile().
## 95%
## 0.6148804## 95%
## TRUEAlkuperäisestä otoksesta laskettu selitysaste on suurempi kuin yllä oleva \(0.95\)-otoskvantiili, joten permutaatiotestin nollahypoteesi hylätään. Halutessasi voit myös laskea permutaatiotestin p-arvon vertaamalla kuinka suuri osuus selitysasteista \(\left\{R_1^2, \ldots, R_m^2\right\}\) on suurempaa kuin alkuperäisestä otoksesta laskettu selitysaste.
## [1] 0Tässä tapauksessa p-arvo on käytännössä nolla.
6.1.2 Parametrien merkitsevyys
Nyt haluamme testata yhden kertoimen merkitsevyyttä \(\beta_j\), \(j\in\{1, \ldots, d\}\), samaan tyyliin kuin koko mallin merkitsevyyttä edellä. Esittelemme siis toisenlaisen permutaatiotestin, jolla testataan seuraavaa nollahypoteesia \(H_0\) vaihtoehtoista hypoteesia \(H_1\) vastaan \[\begin{equation*} \begin{split} &H_0: \beta_j = 0, \\ &H_1: \beta_j \neq 0. \end{split} \end{equation*}\] Nyt emme permutoi vektoreita \(\boldsymbol x_i = (x_{i1}, x_{i2}, \ldots, x_{id})\) vaan ainoastaan parametria \(\beta_j\) vastaavaa selittäjää. Tarkemmin ottaen permutaatiotesti parametrille \(\beta_j\) merkitsevyystasolla \(\alpha\) (esimerkiksi \(\alpha = 0.05\)) suoritetaan seuraavasti.
Olkoon \[\begin{equation*} \left\{\underbrace{(y_1, x_{11}, x_{12}, \ldots, x_{1d})}_{\text{$(d+1)$-ulotteinen havainto nro $1$}}, \ldots, \underbrace{(y_n, x_{n1}, x_{n2}, \ldots, x_{nd})}_{\text{$(d+1)$-ulotteinen havainto nro $n$}}\right\} \end{equation*}\] alkuperäinen otos, jonka otoskoko on \(n\). Kirjoitetaan havainto \(i\) muodossa \((y_i, x_{i1}, x_{i2}, \ldots, x_{id}) = (y_i, \boldsymbol x_i)\), jossa \(\boldsymbol x_i\in\mathbb{R}^d\). Laske selitysaste \(R^2\) alkuperäisestä otoksesta \(\left\{(y_1, \boldsymbol x_1), \ldots, (y_n, \boldsymbol x_n)\right\}\).
Merkitään selittäjää \(j\) vastaavaa otosta notaatiolla \(\boldsymbol x_{\cdot j} = (x_{1j}, \ldots, x_{nj})^T\in\mathbb{R}^n\). Muodosta uusi \(n\) kokoinen otos niin, että jokainen havainto vastaa alkuperäisen otoksen havaintoa \((y_i, \boldsymbol x_i)\) muuten paitsi, että sarakevektori \(\boldsymbol x_{\cdot j}\) on permutoitu.
Askeleen 2 mukaisia permutoituja otoksia on mahdollista muodostaa \(n!\) kappaletta. Muodosta siis kaikki mahdolliset permutoidut otokset.
Laske selitysaste \(R_k^2\) jokaiselle \(k = 1, \ldots, n!\) permutoidulle otokselle.
Järjestä arvot \(R_1^2, \ldots, R_{n!}\) suuruusjärjestykseen. Laske \(\left[(1 - \alpha)\times m\right]\) järjestetty selitysaste. Tässä notaatio \([\cdot]\) tarkoittaa pyöristämistä lähimpään kokonaislukuun. Tarkoitus on siis laskea selitysasteita \(\left\{R_1^2, \ldots, R_{n!}^2\right\}\) vastaava \((1 - \alpha)\)-otoskvantiili. Jos alkuperäisestä otoksesta laskettu \(R^2\) on suurempi kuin laskettu otoskvantiili, niin nollahypoteesi \(H_0\) hylätään.
Huomautus 6.1 pätee myös yllä kuvattuun permutaatiotestille parametrin merkitsevyydelle. Eli yleensä kaikkia mahdollisia permutoituja otoksia ei muodosteta.
Alla sovellamme permutaatiotestiä kertoimen merkitsevyydelle käytännössä.
Esimerkki 6.2 (Permutaatiotesti ja kertoimen merkitsevyys) Käytämme samaa dataa kuin esimerkissä 3.3. Eli meillä on kuvitteellinen \(n = 10\) kokoinen havaintoaineisto. Havainnot ovat toteumia satunnaisvektorista \((Y, X_1, X_2)\), jossa
\(Y = \text{voitto kuukaudessa tuhansina euroina}\) (
profit),\(X_1 = \text{mainosbudjetti kuukaudessa tuhansina euroina}\) (
advertisement) ja\(X_2 = \text{tuotteen hinta tuhansina euroina}\) (
price).
## # A tibble: 10 × 3
## profit advertisement price
## <dbl> <dbl> <dbl>
## 1 -15.2 2.88 4.78
## 2 4.97 7.88 2.27
## 3 -8.51 4.09 3.39
## 4 2.64 8.83 2.86
## 5 13.8 9.40 0.515
## 6 -16.2 0.456 4.50
## 7 5.91 5.28 1.23
## 8 8.85 8.92 0.210
## 9 4.98 5.51 1.64
## 10 -18.5 4.57 4.77Tavoitteenamme on testata lineaarisen regressiomallin
\[\begin{equation*}
\texttt{profit}_i = \beta_0 + \beta_1 \texttt{advertisement}_i + \beta_2 \texttt{price}_i + \varepsilon_i
\end{equation*}\]
kertoimen \(\beta_1\) merkitsevyyttä permutaatiotestillä. Asetamme merkitsevyystasoksi \(\alpha = 0.05\). Ennen kuin kirjoitamme permutaatiotestin algoritmin kokonaisuudessaan, näytämme tarkemmin, miten yksi permutoitu otos muodostetaan. Alla on taas tärkeää asettaa replace = FALSE funktiossa sample().
library(dplyr)
# Sample size
n <- nrow(sale)
# Permutate observations of the advertisement
perm_advertisement <- sale$advertisement[sample(1:n, n, replace = FALSE)]
# Replace original observations of the advertisement with the permuted sample
perm_sample <- sale %>%
mutate(advertisement = perm_advertisement)
perm_sample## # A tibble: 10 × 3
## profit advertisement price
## <dbl> <dbl> <dbl>
## 1 -15.2 5.51 4.78
## 2 4.97 2.88 2.27
## 3 -8.51 9.40 3.39
## 4 2.64 0.456 2.86
## 5 13.8 5.28 0.515
## 6 -16.2 8.92 4.50
## 7 5.91 7.88 1.23
## 8 8.85 8.83 0.210
## 9 4.98 4.57 1.64
## 10 -18.5 4.09 4.77Taulukoissa sale ja perm_sample sarakkeet profit ja price ovat samat. Kuitenkin taulukossa perm_sample sarakkeen advertisement arvot ovat vaihtaneet paikkoja. Esimerkiksi taulukossa sale,
\[\begin{equation*}
2.88 = \texttt{advertisement}_1
\end{equation*}\]
mutta taulukossa perm_sample
\[\begin{equation*}
2.88 = \texttt{advertisement}_2.
\end{equation*}\]
Nyt olemme valmiita kirjoittamaan permutaatiotestin algoritmin askeleet 1–4. Selkeyden vuoksi toteutamme algoritmin for silmukan avulla.
# Number of permutation samples
m <- 1000
# Sample size
n <- nrow(sale)
# Create a vector for storing R^2
rsq_perm <- rep(NA, m)
# Compute R^2 from the original sample
sale_lm_summary <- summary(lm(profit ~ advertisement + price, data = sale))
rsq_original <- sale_lm_summary$r.squared
for (i in 1:m) {
# Construct the ith permuted sample
perm_advertisement <- sale$advertisement[sample(1:n, n, replace = FALSE)]
perm_sample <- sale %>%
mutate(advertisement = perm_advertisement)
# Compute R^2 from the permuted sample
perm_lm_summary <- summary(lm(profit ~ advertisement + price,
data = perm_sample))
rsq_perm[i] <- perm_lm_summary$r.squared
}Vektori rsq_perm sisältää nyt permutaatioituja otoksia vastaavat selitysasteet \(R_1^2, \ldots, R_m^2\).
## [1] 0.9437242 0.9171854 0.9195307 0.9292115 0.9339738 0.9354195Jäljellä on vielä algoritmin askel 5. Haluamme siis laskea \((1-\alpha)\)-otoskvantiilin selitysasteista \(\left\{R_1^2, \ldots, R_m^2\right\}\), kun \(\alpha = 0.05\). Tämän voi helposti suorittaa funktiolla quantile().
## 95%
## 0.9569599## 95%
## FALSEAlkuperäisestä otoksesta laskettu selitysaste on pienempi kuin yllä oleva \(0.95\)-otoskvantiili, joten permutaatiotestin nollahypoteesia ei hylätä. Halutessasi voit myös laskea permutaatiotestin p-arvon vertaamalla kuinka suuri osuus selitysasteista \(\left\{R_1^2, \ldots, R_m^2\right\}\) on suurempaa kuin alkuperäisestä otoksesta laskettu selitysaste.
## [1] 0.103Meillä ei siis ole näyttöä sen puolesta, että mainostus selittäisi voittojen määrää.
Permutaatiotestin tuloksiin liittyy satunnaisuutta, jos kaikkia \(n!\) permutaatioita ei käytetä. Tämän vuoksi jokaisella algoritmin ajolla saat hieman erilaiset luottamusvälit. Tätä havainnollistaa myös kuvat 6.1 ja 6.2.
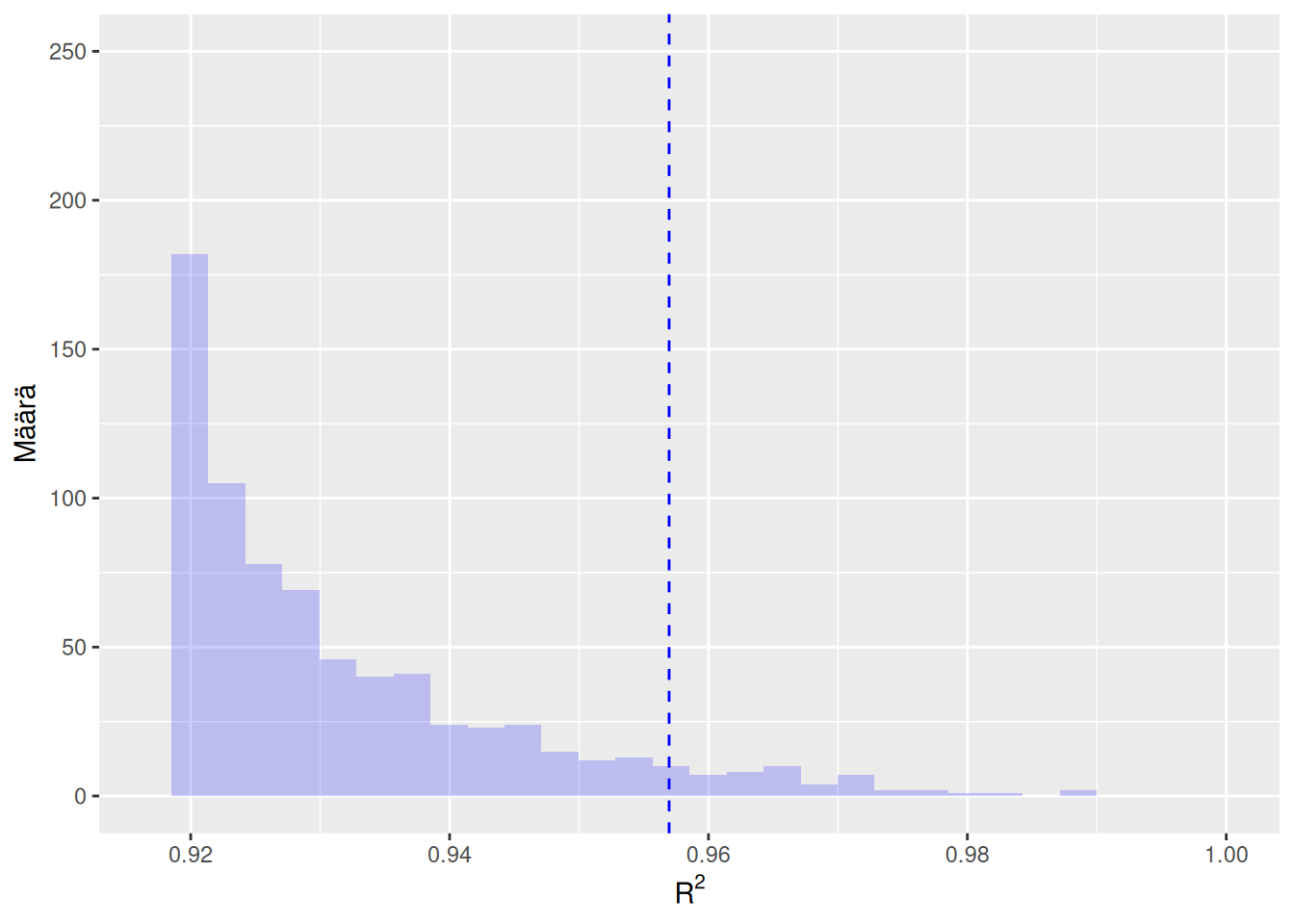
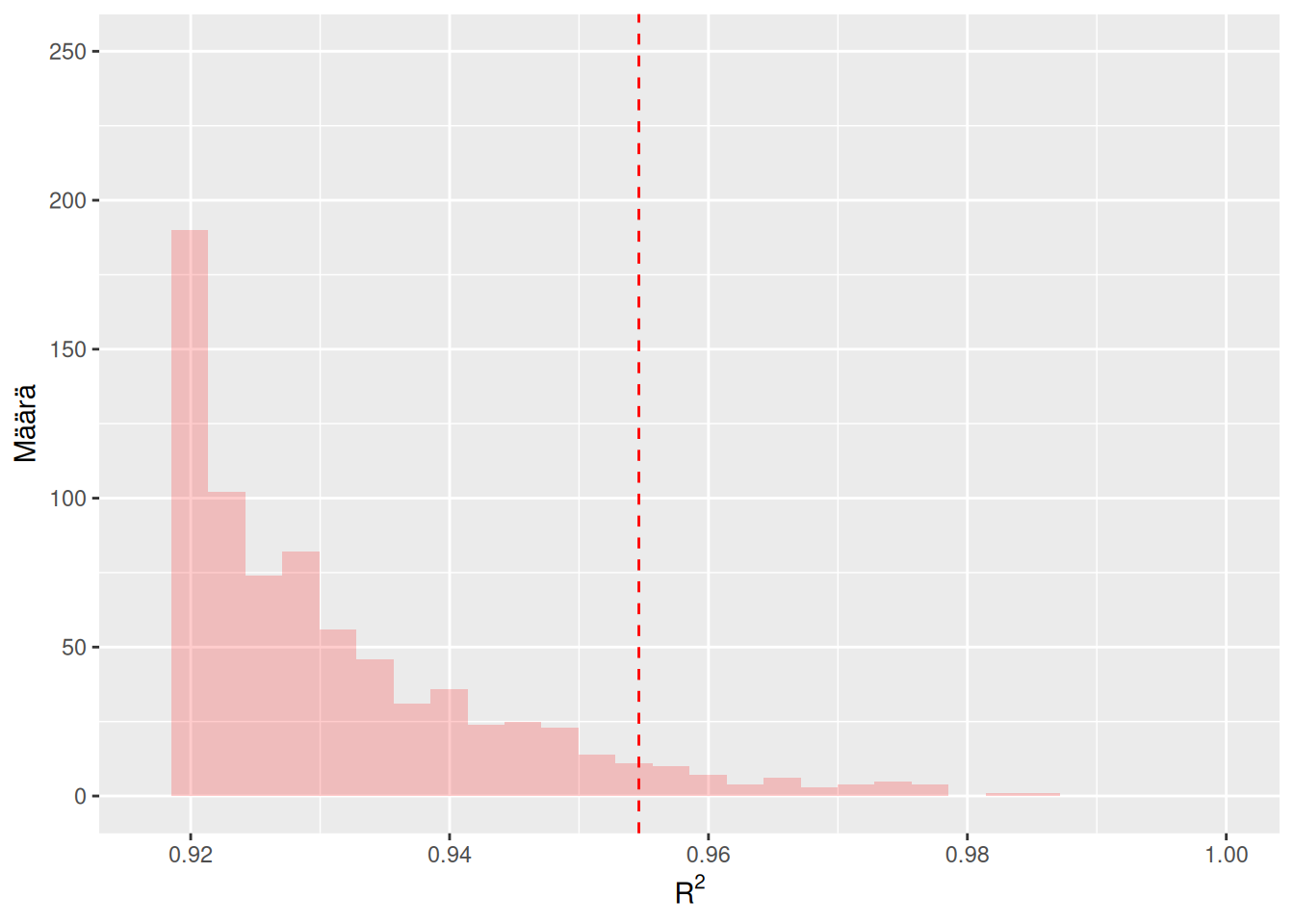
Kuva 6.1: Vasemmassa kuvassa näkyvä sininen histogrammi on muodostettu \(m = 1000\) kappaleesta estimaatteja \(\left\{R_1^2, \ldots, R_m^2\right\}\), jotka laskettiin tässä esimerkissä permutoiduista otoksista. Vasemman kuvan sininen pystyviiva kuvaa \(0.95\)-otoskvantiilia estimaateista \(\left\{R_1^2, \ldots, R_m^2\right\}\). Oikeassa kuvassa permutaatiotesti suoritettiin uudelleen, jolloin saatiin hieman erilaiset \(m = 1000\) estimaattia (punainen histogrammi) ja otoskvantiili (punainen pystyviiva).
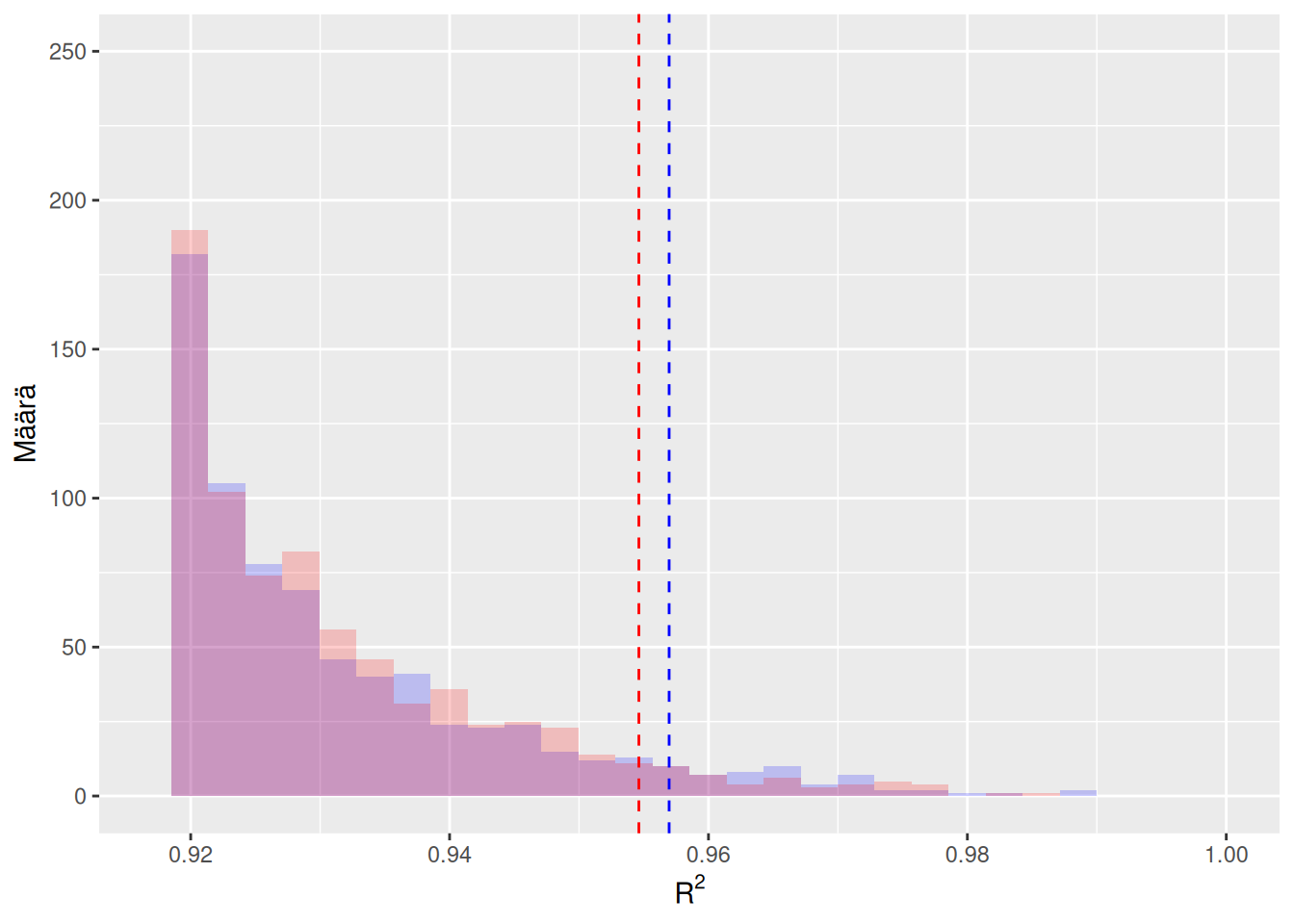
Kuva 6.2: Sama tilanne kuin kuvassa 6.1. Nyt vain histogrammit ja otoskvantiilit ollaan piirretty samaan kuvaan. Tästä kuvasta nähdään selkeämmin, että eri permutaatiotestin ajoilla saadaan hieman erilaiset tulokset.
6.2 Uusiomenetelmä
Luottamusväli on eräs vaihtoehtoinen menetelmä tilastollisen testaamisen rinnalla kuvaamaan parametriin liittyvää epävarmuutta. Tässä tapauksessa olemme kiinnostuneita luottamusväleistä lineaarisen mallin \[\begin{equation*} y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \ldots + \beta_d x_{id} + \varepsilon_i, \quad i\in\{1, \ldots, n\}, \end{equation*}\] vakiotermille \(\beta_0\) ja kertoimille \(\beta_1, \ldots, \beta_j\). Muista, että parametrit \(\beta_j\) ovat vakioita ja luottamusvälit ovat datasta riippuvia satunnaisia välejä. Eli \((1-\alpha)\)-luottamusväli parametrille \(\beta_j\) on satunnainen väli, joka sisältää todellisen parametrin arvon todennäköisyydellä \(1-\alpha\). Esimerkiksi \(0.95\)-luottamusväli voidaan tulkita seuraavasti.
Otoksen \[\begin{equation*} \left\{\underbrace{(y_1, x_{11}, x_{12}, \ldots, x_{1d})}_{\text{$(d+1)$-ulotteinen havainto nro $1$}}, \ldots, \underbrace{(y_n, x_{n1}, x_{n2}, \ldots, x_{nd})}_{\text{$(d+1)$-ulotteinen havainto nro $n$}}\right\} \end{equation*}\] avulla lasketaan \(0.95\)-luottamusväli parametrille \(\beta_j\).
Oletetaan, että sinulla on saatavilla \(99\) ylimääräistä kohdan 1 mukaista otosta. Lasket kaikista otoksista \(0.95\)-luottamusvälin parametrille \(\beta_j\). Lopulta saat siis yhteensä sata \(0.95\)-luottamusväliä.
Koska luottamusväli on satunnainen, niin jokainen väli on hieman erilainen. Lisäksi koska parametrin \(\beta_j\) arvo on tuntematon, niin et tiedä, mitkä lasketuista väleistä peittävät parametrin todellisen arvon. Kuitenkin noin \(95\) lasketuista luottamusväleistä sisältävät parametrin arvon \(\beta_j\). Kuva 6.3 havainnollistaa \(0.95\)-luottamusvälin tulkintaa.
Tarkemmin luottamusvälin käsitettä voit kerrata kurssilta Tilastotieteen perusteet.
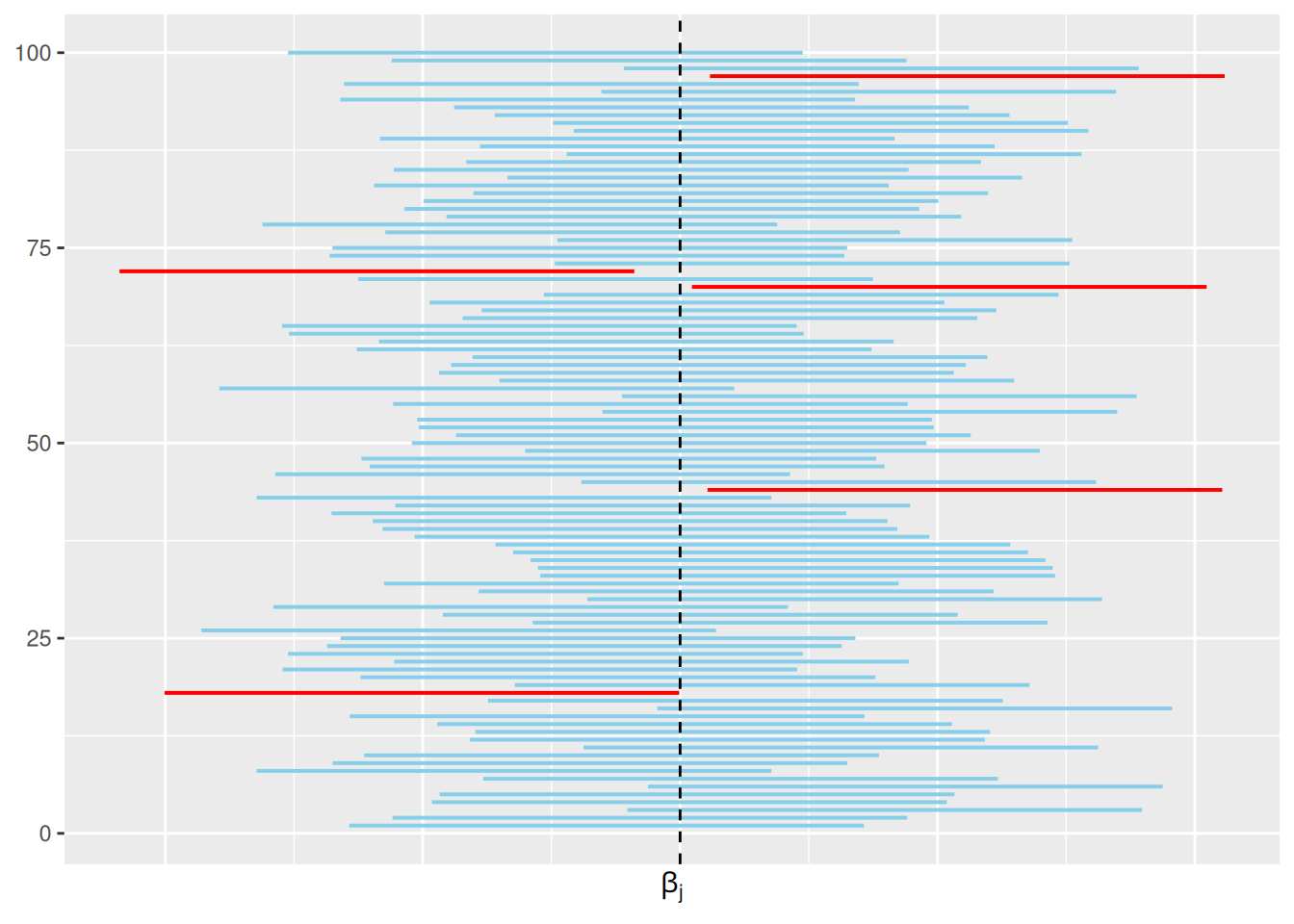
Kuva 6.3: Sata \(0.95\)-luottamusväliä parametrille \(\beta_j\). Siniset välit peittävät parametrin todellisen arvon ja punaiset eivät. Tässä tapauksessa viisi väliä sadasta eivät sisällä parametria \(\beta_j\).
Tässä olemme kiinnostuneita luottamusvälin laskemisesta parametrille \(\beta_j\) uusiomenetelmällä (eng: bootstrap method), joka on epäparametrinen menetelmä luottamusvälien muodostamiseen. Alla kuvaamme, kuinka \((1-\alpha)\)-luottamusväli muodostetaan parametrille \(\beta_j\) uusiomenetelmällä askel askeleelta.
Olkoon \[\begin{equation*} \overrightarrow{Z}^{(1)} = \left\{(y_1, x_{11}, x_{12}, \ldots, x_{1d}), \ldots, (y_n, x_{n1}, x_{n2}, \ldots, x_{nd})\right\} \end{equation*}\] alkuperäinen otos, jonka otoskoko on \(n\). Muodosta uusi \(n\) kokoinen otos \(\overrightarrow{Z}^{(2)}\) palautusotannalla alkuperäisestä otoksesta \(\overrightarrow{Z}^{(1)}\). Uutta otosta \(\overrightarrow{Z}^{(2)}\) kutsumme uusio-otokseksi (eng: bootstrap sample).
- Palautusotanta: valitset havaintoja (vektoreita) \((y_i, x_{i1}, x_{i2}, \ldots, x_{id})\) alkuperäisestä otoksestä satunnaisesti niin, että sama havainto voidaan valita useampaan kertaan.
Laske estimaatti \(\hat{\boldsymbol\beta}^{(2)} = \left(\hat\beta_0^{(2)}, \hat\beta_1^{(2)}, \ldots, \hat\beta_d^{(2)}\right)^T\) muodostetusta uusio-otoksesta \(\overrightarrow{Z}^{(2)}\).
Toista edelliset askeleet \(m - 1\) kertaa (esimerkiksi \(m = 1000\)).
- Mitä suurempi \(m\), sitä parempi estimaatti luottamusvälille saadaan. Kuitenkin mitä suurempi \(m\) arvo, sitä pidempään uusiomenetelmän suorittamisessa kestää tietokoneelta.
Nappaa alkuperäisen otoksen \(\overrightarrow{Z}^{(1)}\) avulla laskettu estimaatti \(\hat\beta_j^{(1)}\) parametrille \(\beta_j\). Poimi myös uusio-otosten avulla lasketut estimaatit \(\hat\beta_j^{(2)}, \ldots, \hat\beta_j^{(m)}\).
Järjestä estimaatit \(\hat\beta_j^{(1)}, \hat\beta_j^{(2)}, \ldots, \hat\beta_j^{(m)}\) suuruusjärjestykseen. Aseta luottamusvälin alapääksi \(\left[\frac{\alpha}{2}\times m\right]\) järjestetty estimaatti. Aseta luottamusvälin yläpääksi \(\left[\frac{\alpha}{2}\times m\right]\) järjestetty estimaatti. Tässä notaatio \([\cdot]\) tarkoittaa pyöristämistä lähimpään kokonaislukuun. Tarkoitus on siis laskea estimaatteja \(\left\{\hat\beta_j^{(1)}, \hat\beta_j^{(2)}, \ldots, \hat\beta_j^{(m)}\right\}\) vastaavat \(\alpha/2\)- ja \((1 - \alpha/2)\)-otoskvantiilit.
Uusiomenetelmän ideana on siis luoda uusia otoksia alkuperäisestä otoksesta, joiden avulla laskettuja estimaatteja käytetään luottamusvälin muodostamiseen. Englanninkielinen nimitys bootstrap viittaakin itsensä nostamiseen ylös suosta vetämällä tarpeeksi kovaa omista kengännauhoista. Tämä on tietenkin fyysisesti mahdotonta mutta kuvaa hyvin sitä, kuinka uusiomenetelmässä luodaan uusia otoksia alkuperäistä. Alla sovellamme uusiomenetelmää käytännössä.
Esimerkki 6.3 (Uusiomenetelmä) Käytämme samaa dataa kuin esimerkissä 3.3. Eli meillä on kuvitteellinen \(n = 10\) kokoinen havaintoaineisto. Havainnot ovat toteumia satunnaisvektorista \((Y, X_1, X_2)\), jossa
\(Y = \text{voitto kuukaudessa tuhansina euroina}\) (
profit),\(X_1 = \text{mainosbudjetti kuukaudessa tuhansina euroina}\) (
advertisement) ja\(X_2 = \text{tuotteen hinta tuhansina euroina}\) (
price).
## # A tibble: 10 × 3
## profit advertisement price
## <dbl> <dbl> <dbl>
## 1 -15.2 2.88 4.78
## 2 4.97 7.88 2.27
## 3 -8.51 4.09 3.39
## 4 2.64 8.83 2.86
## 5 13.8 9.40 0.515
## 6 -16.2 0.456 4.50
## 7 5.91 5.28 1.23
## 8 8.85 8.92 0.210
## 9 4.98 5.51 1.64
## 10 -18.5 4.57 4.77Tavoitteenamme on laskea \(0.95\)-luottamusväli uusiomenetelmällä lineaarisen regressiomallin
\[\begin{equation*}
\texttt{profit}_i = \beta_0 + \beta_1 \texttt{advertisement}_i + \beta_2 \texttt{price}_i + \varepsilon_i
\end{equation*}\]
kertoimelle \(\beta_2\). Ennen kuin kirjoitamme uusiomenetelmä algoritmin kokonaisuudessaan, kuvailemme tarkemmin muutamaa tärkeää askelta. Alkuperäisestä otoksesta laskettu estimaatti parametrille \(\beta_2\) saadaan napattua lm() funktion tuottamasta muuttujasta.
# Fit model
sale_lm <- lm(profit ~ advertisement + price, data = sale)
# Inspect how to pick beta2
names(sale_lm)## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "xlevels" "call" "terms" "model"## (Intercept) advertisement price
## 5.885823 1.032046 -5.191414## price
## -5.191414Seuraavaksi näytämme, miten yksi uusio-otos muodostetaan. Uusio-otoksen voi muodostaa valitsemalla rivejä alkuperäisestä taulukosta käyttämällä funktiota sample(). On erittäin tärkeää, että funktiossa sample() asetat replace = TRUE. Tällöin on mahdollista valita sama havainto (eli rivi) useamman kerran.
## # A tibble: 10 × 3
## profit advertisement price
## <dbl> <dbl> <dbl>
## 1 -8.51 4.09 3.39
## 2 -8.51 4.09 3.39
## 3 -18.5 4.57 4.77
## 4 4.97 7.88 2.27
## 5 -16.2 0.456 4.50
## 6 13.8 9.40 0.515
## 7 2.64 8.83 2.86
## 8 -16.2 0.456 4.50
## 9 4.98 5.51 1.64
## 10 -18.5 4.57 4.77Vertaamalla muuttujia sale ja boot_sample huomataan, että kaikki taulukon boot_sample rivit ovat taulukon sale rivejä. Kuitenkin taulukossa boot_sample sama rivi voi esiintyä useamman kerran. Uusio-otoksesta saadaan laskettua estimaatti kertoimelle \(\beta_2\) samaan tyyliin kuin alkuperäisen otoksen avulla.
Nyt olemme valmiita kirjoittamaan uusiomenetelmä algoritmin askeleet 1–4. Selkeyden vuoksi toteutamme algoritmin for silmukan avulla.
# Number of repetitions (including the estimate from the original sample)
m <- 1000
# Sample size
n <- nrow(sale)
# Create a vector for storing all the estimates
beta_boot <- rep(NA, m)
# Compute the parameter estimate from the original sample and store it
sale_lm <- lm(profit ~ advertisement + price, data = sale)
beta_boot[1] <- sale_lm$coefficients[3]
for (i in 2:m) {
# Construct the ith bootstrap sample and formulate the corresponding
# linear regression model
boot_sample <- sale[sample(1:n, n, replace = TRUE), ]
boot_lm <- lm(profit ~ advertisement + price, data = boot_sample)
# Compute the parameter estimate from the bootstrap sample and store it
beta_boot[i] <- boot_lm$coefficients[3]
}Vektori beta_boot sisältää nyt alkuperäisellä otoksella lasketun estimaatin \(\hat\beta_2^{(1)}\) parametrille \(\beta_2\) ja vastaavat uusio-otoksista lasketut estimaatit \(\hat\beta_2^{(2)}, \ldots, \hat\beta_2^{(m)}\).
## [1] -5.191414 -7.197275 -5.941904 -5.981090 -6.093608 -3.877759Jäljellä on vielä algoritmin 5 askel. Eli haluamme laskea \(\alpha/2\)- ja \((1 - \alpha/2)\)-otoskvantiilit estimaateista \(\left\{\hat\beta_1^{(2)}, \hat\beta_2^{(2)}, \ldots, \hat\beta_2^{(m)}\right\}\), kun \(\alpha = 0.05\). Tämän voimme suorittaa helposti funktiolla quantile().
## 2.5% 97.5%
## -7.115774 -3.163906Nyt vektori boot_ci sisältää luottamusvälin ala- ja ylärajan. Eli parametrille \(\beta_2\) saimme \(0.95\)-luottamusväliksi \(\approx [-7.1, -3.2]\).
Huomaa, että uusio-otoksien muodostamiseen (koodissa boot_sample) liittyy satunnaisuutta. Tämän vuoksi jokaisella algoritmin ajolla saat hieman erilaiset luottamusvälit. Tätä havainnollistaa myös kuvat 6.4 ja 6.5.
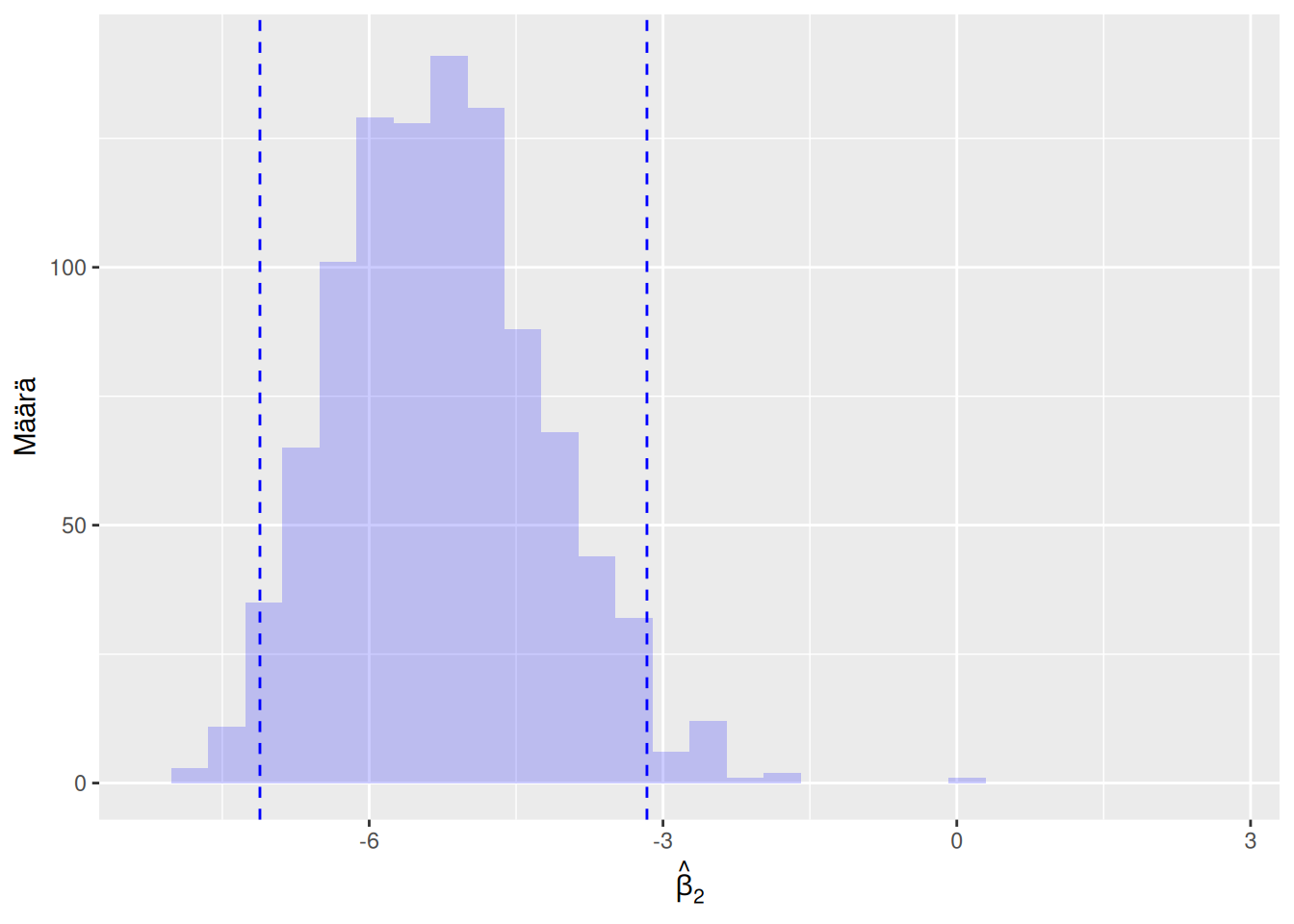
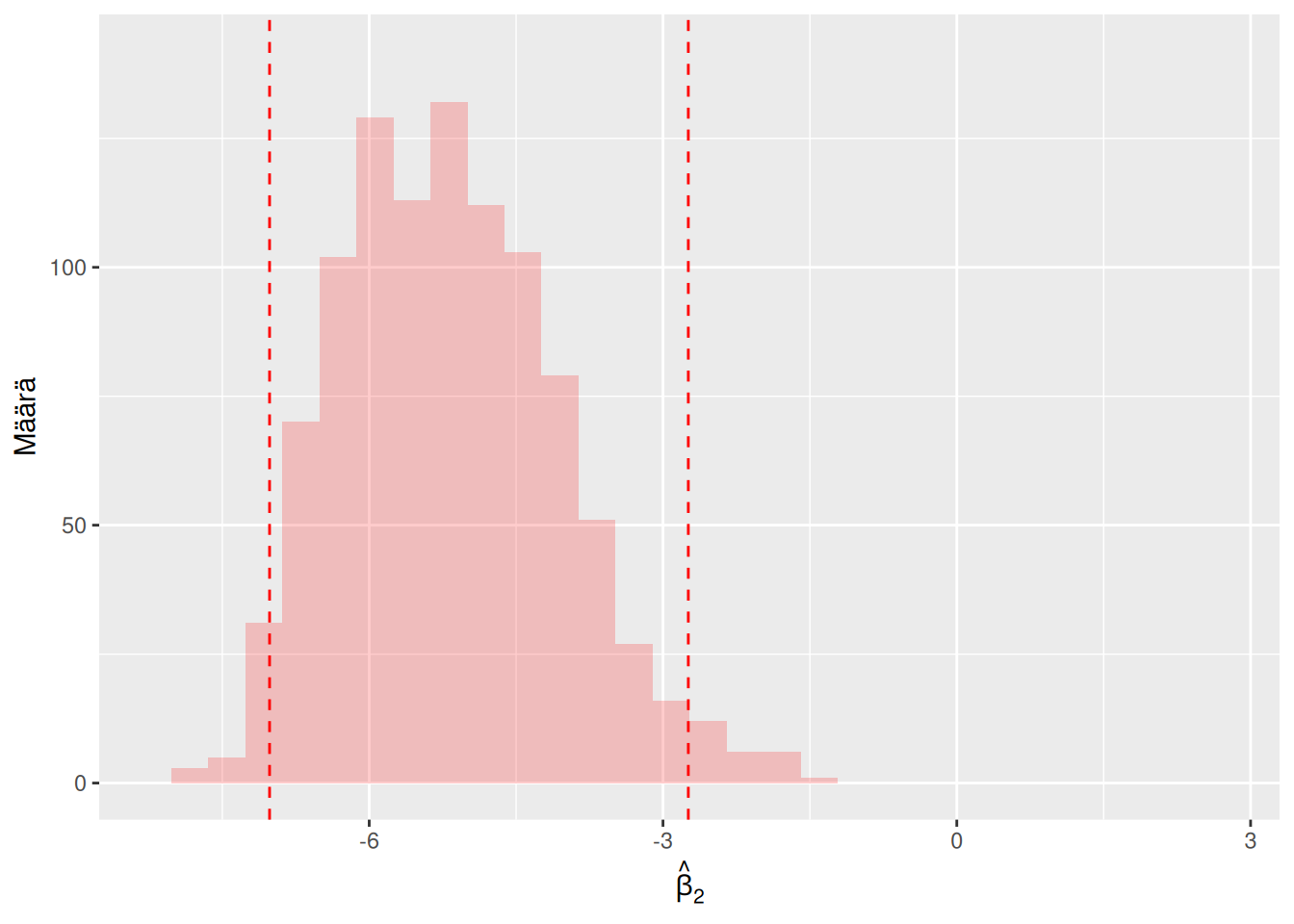
Kuva 6.4: Vasemmassa kuvassa näkyvä sininen histogrammi on muodostettu \(m = 1000\) kappaleesta estimaatteja \(\left\{\hat\beta_2^{(1)}, \hat\beta_2^{(2)}, \ldots, \hat\beta_2^{(m)}\right\}\), jotka laskettiin tässä esimerkissä. Vasemman kuvan siniset pystyviivat kuvaavat \(0.95\)-luottamusvälin ylä- ja alarajaa. Oikeassa kuvassa uusiomenetelmä suoritettiin uudelleen, jolloin saatiin hieman erilaiset \(m = 1000\) estimaattia (punainen histogrammi) ja luottamusväli (punaiset pystyviivat).
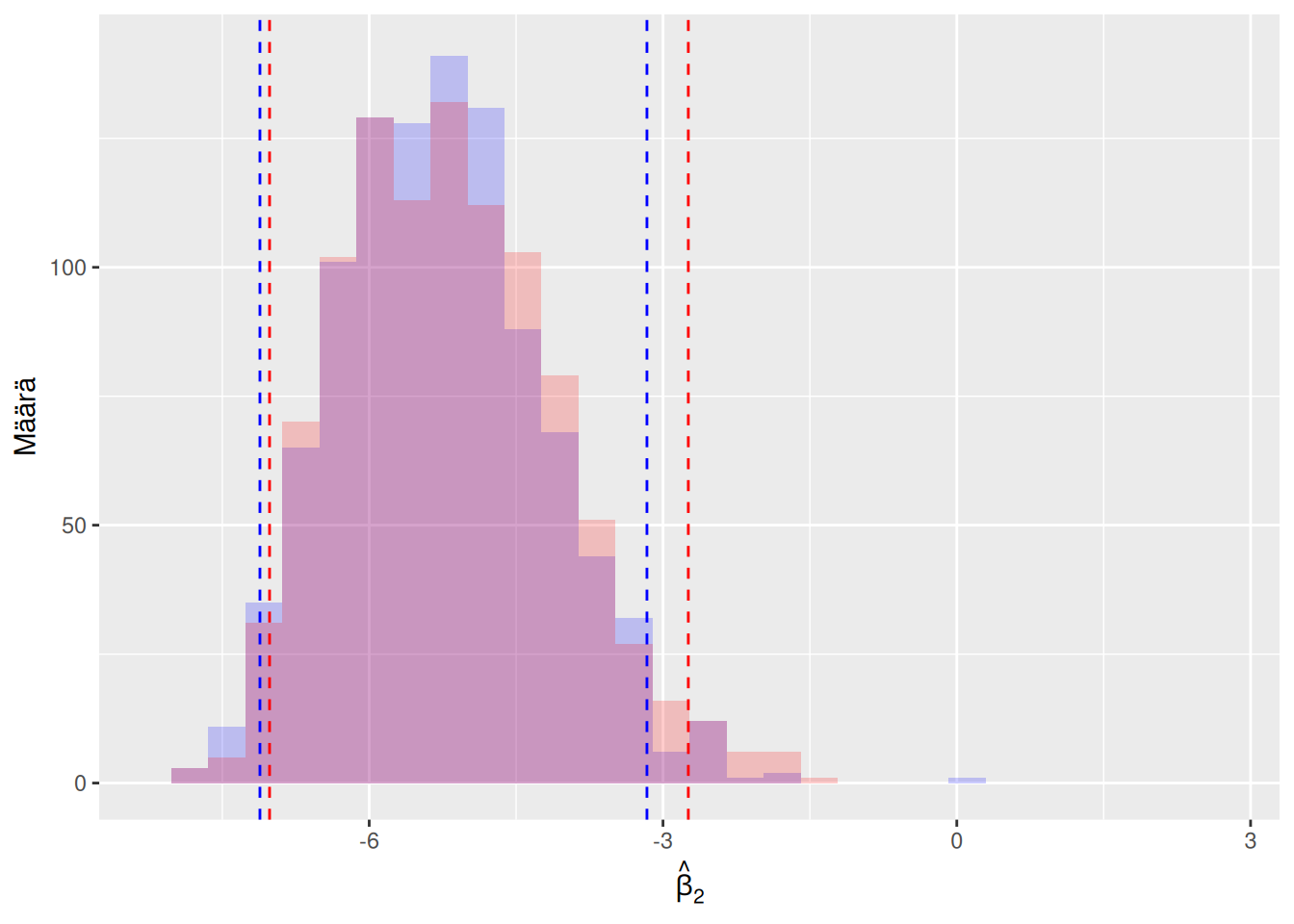
Kuva 6.5: Sama tilanne kuin kuvassa 6.4. Nyt vain histogrammit ja luottamusvälit ollaan piirretty samaan kuvaan. Tästä kuvasta nähdään selkeämmin, että eri uusiomenetelmän ajoilla saadaan hieman erilaiset tulokset.
Huomautus 6.2 Uusiomenetelmää voidaan käyttää myös muunlaisten luottamusvälien laskemiseen. Esimerkiksi lineaarisen mallin ennustuksille voidaan laskea luottamusvälit käyttämällä uusiomenetelmää. Uusiomenetelmä ei ole myöskään sidoksissa lineaariseen regressioon vaan menetelmää voidaan käyttää muissa yhteyksissä. Kuitenkin tällä kurssilla käytämme uusiomenetelmää ainoastaan luottamusvälien laskemiseen lineaarisen mallin parametreille \(\beta_j\).
Huomaa myös, että oletuksen 3.1 alla parametreille \(\beta_j\) voidaan laskea parametrinen luottamusväli. Tämä jätetään kuitenkin kurssin ulkopuolelle, koska parametristen luottamusvälien laskemisen filosofiaa käytiin kurssilla Tilastotieteen perusteet.