Luku 5 Epäparametrisia tilastollisia testejä
Sekä Tilastotieteen perusteissa että tällä kurssilla ollaan tähän asti keskitytty parametrisiin tilastollisiin testeihin. Parametrisissa tilastollisissa testeissä oletetaan, että satunnaisotos \(X_1, X_2, \ldots, X_n\) noudattaa jotain tunnettua jakaumaa \(F_{\boldsymbol\theta}(x) = \mathbb{P}(X\leq x)\), jossa parametrivektori \(\boldsymbol\theta\in\mathbb{R}^d\) määrittää jakauman \(F_{\boldsymbol\theta}\). Esimerkiksi jos oletetaan että satunnaisotos ollaan generoitu normaalijakaumasta \(N(\mu, \sigma^2)\), niin \(\boldsymbol\theta = (\mu, \sigma^2)^T\in\mathbb{R}^d\) ja voimme testata nollahypoteesia \(H_0: \mu = \mu_0\) vaihtoehtoista hypoteesia \(H_1: \mu \neq \mu_0\) vastaan t-testin avulla.
Aina emme kuitenkaan tiedä datan generoivaa jakaumaa. Eli emme voi olettaa datan tulevan normaalijakaumasta, tasajakaumasta, eksponenttijakaumasta tai mistä tahansa muusta jakaumasta. Yllättävää kyllä, myös tämäntyyppisiin tilanteisiin on olemassa tilastollisia testejä. Epäparametriset (eng: nonparametric) testit, joita käsitellään tässä luvussa, eivät oleta datan tulevan mistään tietystä jakaumasta.
Luvuissa 5.1 ja 5.2 käsittelemme kahta erillistä epäparametrista testiä liittyen jakauman sijaintiin. Luvuissa 5.3 ja 5.4 käsittelemme kahden tai useamman eri jakauman vertailua eräiden epäparametristen testien avulla. Lisätietoa luvun aiheista löydät esimerkiksi kirjan Introduction to probability and statistics for engineers and scientists luvusta 12 (Ross 2021).
5.1 Merkkitesti
Olkoon \(X\) satunnaismuuttuja, joka noudattaa jatkuvaa jakaumaa \(F = \mathbb{P}\left(X\leq x\right)\) ja olkoon \(m\) jakauman \(F\) mediaani. Toisin sanoen \(m\in\mathbb{R}\) on luku niin, että \(F(m) = 0.5\). Olemme kiinnostuneita testaamaan seuraavaa nollahypoteesia \(H_0\) vaihtoehtoista hypoteesia \(H_1\) vastaan \[\begin{align} \tag{5.1} &H_0: m = m_0, \\ &H_1: m \neq m_0. \end{align}\] Kuten t-testissä, olemme nyt myös kiinnostuneita jakauman sijainnista. Tässä tapauksessa jakauman sijainnin mittarina käytämme kuitenkin mediaania emmekä odotusarvoa kuten t-testissä. Symmetrisille jakaumille mediaani ja odotusarvo ovat yhtä suuria, mutta kuten kuva 5.1 näyttää, epäsymmetrisen jakauman mediaani ja odotusarvo voivat olla erisuuria. Täten mediaani ja odotusarvo kuvaavat jakauman sijaintia hieman eri tavoin.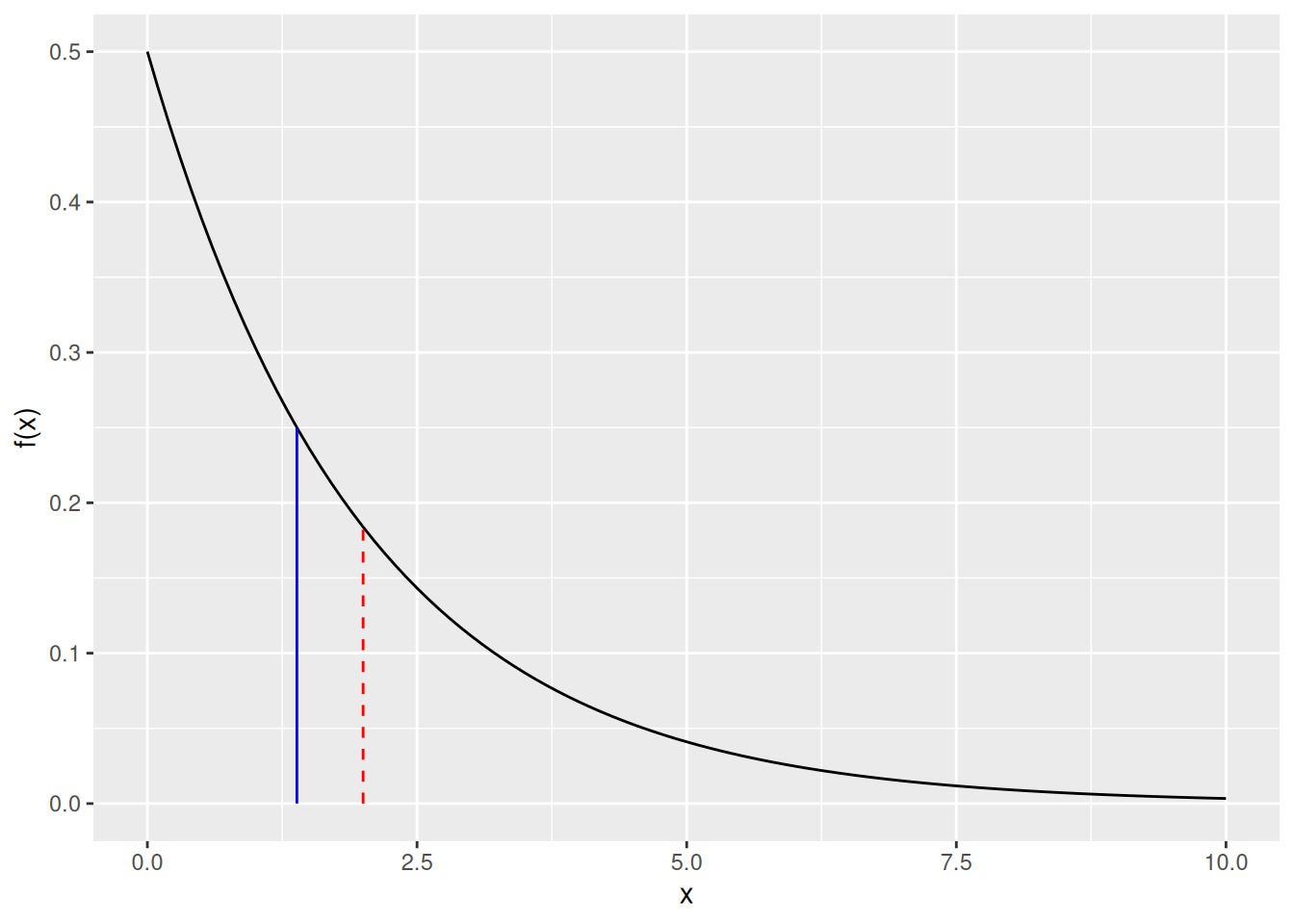
Kuva 5.1: Musta viiva antaa erään eksponenttijakauman tiheysfunktion (rate \(\lambda = 0.5\)). Jakauman odotusarvoa (\(1/\lambda = 2\)) kuvaa punainen katkonainen pystyviiva ja mediaania (\(\ln(2) / \lambda \approx 1.39\)) sininen kiinteä pystyviiva.
Olkoon \(\overrightarrow{X} = \{X_1, \ldots, X_n\}\) otos riippumattomia havaintoja satunnaismuuttujasta \(X\). Kaavan (5.1) hypoteeseja voidaan testata seuraavalla idealla. Mediaanin määritelmän mukaan, nollahypoteesin alla noin puolet havainnoista ovat pienempiä kuin \(m_0\) ja puolet havainnoista ovat suurempia kuin \(m_0\). Tämän idean muotoilu matemaattisesti johtaa niin kutsuttuun merkkitestiin (eng: sign test). Määritellään osoitinmuuttuja \[\begin{equation*} \mathrm{I}_i = \begin{cases} 1 & \text{jos}\ X_i < m_0, \\ 0, & \text{jos}\ X_i \geq m_0, \end{cases} \end{equation*}\] joka kertoo onko havainto \(X_i\) suurempi vai pienempi kuin mediaani nollahypoteesin alla. Testisuureessa lasketaan, kuinka monta havaintoa jää arvon \(m_0\) alapuolelle. Eli testisuureen määritellään olevan \[\begin{equation*} \tag{5.2} T = \sum_{i = 1}^n \mathrm{I}_i. \end{equation*}\]
Alla näytetään esimerkki merkkitestin testisuureen laskemisesta.
Esimerkki 5.1 (Merkkitestin testisuure) Taulukon 5.1 ensimmäisessä sarakkeessa näkyy otos erään yrityksen työntekijöiden palkoista. Otoksen koko on \(n = 10\). Otoksen avulla haluamme testata, onko näyttöä sitä vastaan, että yrityksen työntekijöiden mediaanipalkka on \(m_0 = 3200\) euroa. Taulukosta näemme, että kahden työntekijän palkka on pienempi kuin \(m_0\), joten testisuureeksi saadaan \(t = 2\). Merkkitestin nimi tuleekin siitä, että testisuuretta laskettaessa tarkastellaan erotuksien \(\texttt{salary}_i - m_0\) merkkejä (\(+\) tai \(-\)). Testisuure on siis miinus merkkien määrä.
| Palkka | \(\texttt{salary}_i - m_0\) | Erotuksen merkki |
|---|---|---|
| 3000 | -200 | \(-\) |
| 5400 | 2200 | \(+\) |
| 3300 | 100 | \(+\) |
| 7300 | 4100 | \(+\) |
| 10000 | 6800 | \(+\) |
| 2600 | -600 | \(-\) |
| 3600 | 400 | \(+\) |
| 7600 | 4400 | \(+\) |
| 3700 | 500 | \(+\) |
| 3500 | 300 | \(+\) |
Huomioi, että palkkajakauman sijaintiin liittyvissä tilastollisissa testeissä t-testin käyttäminen on usein hyvin arvelluttavaa, koska
palkkajakaumat ovat usein epäsymmetrisiä (toisin kuin normaalijakauma) ja
jakauman oikea häntä on usein paksu (todella korkeita palkkoja esiintyy enemmän, mitä odottaisi normaalijakauman alla),
mutta t-testissä palkkojen jakaumaksi oletettaisiin nimenomaan normaalijakauma! Merkkitestissä ainoa palkkojen jakaumaan liittyvä oletus on jatkuvuus.
Jos nollahypoteesi pätee, niin testisuureen odotusarvo on \(\mathbb{E}(T) = n/2\), koska puolet havainnoista ovat pienempiä kuin \(m_0\) ja puolet ovat suurempia kuin \(m_0\). Toisaalta jos testisuure poikkeaa paljolti arvosta \(n/2\), niin meillä on näyttöä nollahypoteesia vastaan. Itseasiassa voimme sanoa testisuureesta paljon enemmän. Kaavan testisuureen (5.2) laskeminen muistuttaa tilannetta, jossa heitämme kolikkoa monta kertaa peräkkäin ja laskemme esimerkiksi klaavojen määrän \(n\) heiton jälkeen – tässä tapauksessa emme kuitenkaan laske klaavojen määrää vaan sitä, kuinka moni havainto on pienempää kuin \(m_0\). Eli testisuure noudattaa binomijakaumaa \(T\sim \mathrm{Bin}(n, p)\). Kun binomijakauman parametreiksi asetetaan \(n\) (vrt. “kolikon heittojen määrä”) ja \(p\) (vrt. “todennäköisyys saada klaava”), niin binomijakauman pistetodennäköisyysfunktio on
\[\begin{equation*}
p_T(t) = \mathbb{P}\left(T = t\right) = \binom{n}{t} p^t(1 - p)^{n-t},
\quad t\in\{0, 1, 2, \ldots, n\},
\end{equation*}\]
jossa \(\binom{n}{t}\) on binomikerroin. Kuten jo todettua, niin nollahypoteesin alla todennäköisyys saada negatiivinen erotus \(X_i - m_0\) on \(1/2\). Tämän vuoksi kaavan (5.1) hypoteesit ovat yhtäpitäviä seuraavien hypoteesien kanssa
\[\begin{align*}
&H_0: p = 1/2, \\
&H_1: p \neq 1/2,
\end{align*}\]
jossa \(T\sim \mathrm{Bin}(n, p)\). Eli merkkitestissä testaamme vain sitä, onko negatiivisten erotuksien \(X_i - m_0\) suhteellinen osuus \(50\%\). Nyt p-arvo voidaan laskea käsin tai käyttäen R:n funktiota binom.test().
Esimerkki 5.2 (Merkkitestin p-arvo) Jatketaan esimerkkiä 5.1, jossa havaittu testisuure on \(t = 2\) ja otoskoko on \(n = 10\). Nollahypoteesin alla testisuure noudattaa jakaumaa \(\mathrm{Bin}(10, 1/2)\). Muista, että p-arvo antaa todennäköisyyden havaita poikkeavimpia tai yhtä poikkeavia testisuureen arvoja kuin \(t\) nollahypoteesin alla \(H_0\). Tässä tapauksessa poikkeavuutta mitataan etäisyytenä testisuureen odotusarvosta \(\mathbb{E}(T) = 5\). Havaitun testisuureen etäisyys odotusarvosta on \(5 - 2 = 3\) ja arvoilla \(\{0, 1, 2, 8, 9, 10\}\) etäisyys on sama tai vielä suurempi. Kuvassa 5.2 ollaan havainnollistettu poikkeavat arvot \(\{0, 1, 2, 8, 9, 10\}\) pinkeillä palloilla.
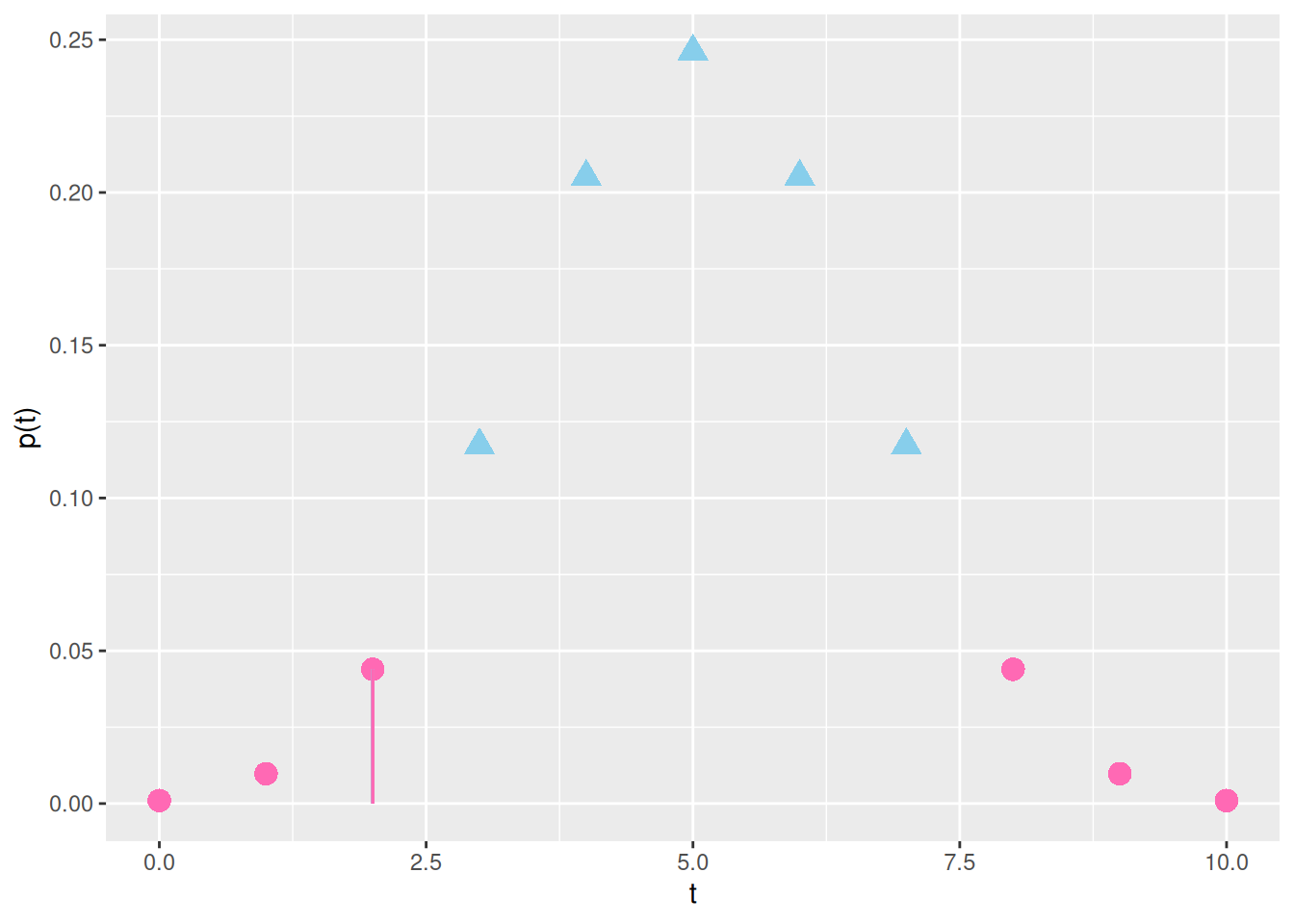
Kuva 5.2: Binomijakauman \(\mathrm{Bin}(10, 1/2)\) pistetodennäköisyysfunktio \(p_T(t)\) arvoilla \(t\in\{0, 1, \ldots, 10\}\). Pinkki viiva vastaa testisuureen arvoa (\(x\)-akselilla \(t = 2\)). Pinkit pallot vastaavat niitä arvoja, jotka ovat poikeavampia tai yhtä poikkeavia kuin havaittu testisuure. Siniset kolmiot ovat niitä arvoja joita ei oteta mukaan p-arvon laskemiseen.
Eli p-arvo voidaan laskea kaavalla \[\begin{equation*} \sum_{t\in A} p_T(t), \end{equation*}\] jossa \(A = \{0, 1, 2, 8, 9, 10\}\) ja \(p_T\) on jakauman \(\mathrm{Bin}(n, p)\) pistetodennäköisyysfunktio.
## [1] 0.109375Koska binomijakauma \(\mathrm{Bin}(10, 1/2)\) on symmetrinen odotusarvon \(5\) suhteen, niin p-arvo voidaan myös sieventää muotoon \[\begin{equation*} 2\mathbb{P}\left(T\leq 2\right), \end{equation*}\] joka voidaan näppärästi laskea binomijakauman kertymäfunktion avulla.
## [1] 0.109375Kuitenkin yleensä merkkitesti suoritetaan R:n funktiolla binom.test(), joka ottaa sisäänsä testisuureen \(t = 2\), otoskoon \(n = 10\) ja todennäköisyyden \(\mathbb{P}(X_i\leq m_0)\), joka on \(1/2\) nollahypoteesin alla.
##
## Exact binomial test
##
## data: t and n
## number of successes = 2, number of trials = 10, p-value = 0.1094
## alternative hypothesis: true probability of success is not equal to 0.5
## 95 percent confidence interval:
## 0.02521073 0.55609546
## sample estimates:
## probability of success
## 0.2Joka tapauksessa p-arvoksi saadaan \(\approx 0.11\). Tällöin esimerkiksi merkitsevyystasolla \(\alpha = 0.05\) meillä ei ole tarpeeksi näyttöä nollahypoteesin (mediaanipalkka on \(3200\) euroa) hylkäämiseen.
Huomautus 5.1 (Normaaliaproksimaatio) Suurella otoskoolla merkkitesti voidaan myös suorittaa normaaliaproksimaation (p-arvo lasketaan normaalijakaumasta) avulla samaan tapaan kuin “testi suhteelliselle osuudelle” kurssilla Tilastotieteen perusteet. Normaaliapproksimaatio oli käytännön kannalta hyödyllinen aikana, jolloin tehokkaita tietokoneita ei ollut, minkä vuoksi p-arvon laskeminen testisuureen tarkan jakauman eli binomijakauman avulla saattoi olla vaikeaa.
Aivan kuten t-testin tapauksessa, voimme suorittaa yksisuuntaisen merkkitestin esimerkiksi hypoteeseilla \[\begin{align} &H_0: m = m_0, \\ &H_1: m > m_0. \end{align}\] Merkkitestillä voidaan myös vertailla kahden ryhmän mediaaneja, jos havainnot ovat parittaisia. Oletetaan, että olemme havainneet kaksi otosta \(\overrightarrow{X} = \{X_1, \ldots, X_n\}\) ja \(\overrightarrow{Y} = \{Y_1, \ldots, Y_n\}\), joiden otoskoot ovat yhtäsuuret. Lisäksi oletetaan, että
Parin \((X_i, Y_i)^T\) sisällä saa olla riippuvuutta mutta
parit \(\{(X_1, Y_1)^T, (X_2, Y_2)^T, \ldots, (X_n, Y_n)^T\}\) ovat riippumattomia, ja
erotukset \(X_i - Y_i\) (tai \(Y_i - X_i\)) noudattavat jatkuvaa jakaumaa.
Tällöin kahden ryhmän mediaanien yhtäsuuruutta voidaan testata parittaisella merkkitestillä. Parittainen merkkitesti on vain yhden otoksen merkkitesti erotuksille \(X_i - Y_i\). Viikon 7 tehtävässä 1 suoritetaan parittainen yksisuuntainen merkkitesti askel askeleelta.
5.2 Merkkisijatesti
Olkoon \(X\) satunnaismuuttuja, joka noudattaa jatkuvaa jakaumaa \(F = \mathbb{P}\left(X\leq x\right)\). Jakauman \(F\) mediaanin lisäksi ollaan usein kiinnostuneita siitä, onko jakauma symmetrinen mediaanin suhteen. Olemme siis kiinnostuneita testaamaan seuraavaa nollahypoteesia \(H_0\) vaihtoehtoista hypoteesia \(H_1\) vastaan \[\begin{align*} &H_0: \text{Satunnaismuuttujan $X$ jakauma $F$ on symmetrinen arvon $m_0$ suhteen}, \\ &H_1: \text{Satunnaismuuttujan $X$ jakauma $F$ ei ole symmetrinen arvon $m_0$ suhteen}. \end{align*}\] Formaalisti nollahypoteesit voidaan ilmaista seuraavasti \[\begin{align*} &H_0: \mathbb{P}\left(X \leq m_0 - a\right) = \mathbb{P}\left(X \geq m_0 + a\right) \quad \text{kaikille}\ a\in\mathbb{R}, \\ &H_1: \mathbb{P}\left(X \leq m_0 - a\right) \neq \mathbb{P}\left(X \geq m_0 + a\right) \quad \text{jollekin}\ a\in\mathbb{R}. \end{align*}\] Kuva 5.3 havainnollistaa nollahypoteesin tilannetta.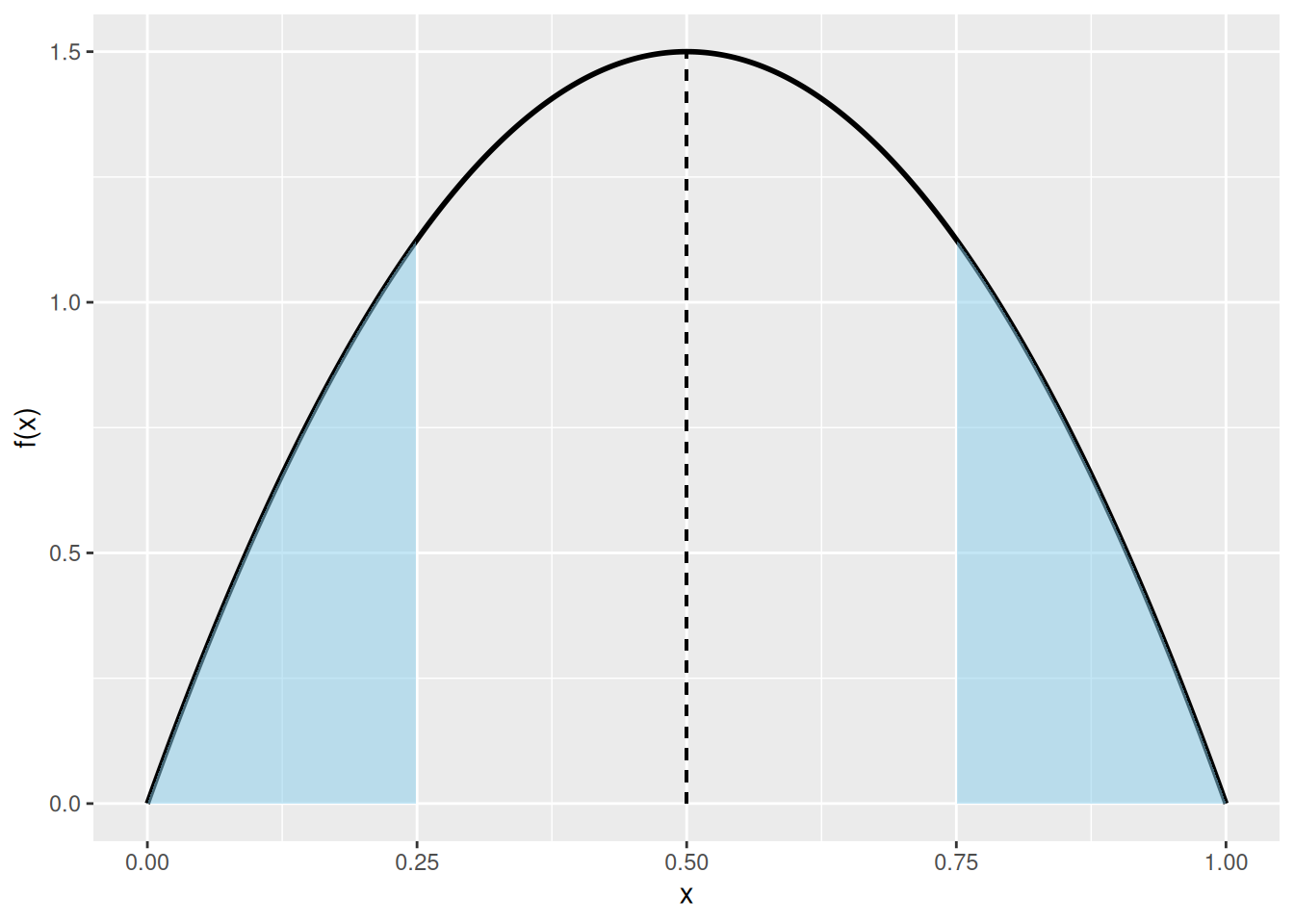
Kuva 5.3: Kiinteä musta käyrä kuvaa erään symmetrisen jakauman tiheysfunktiota. Kuvassa ollaan asetettu \(m_0 = 0.5\) ja \(a = 0.25\). Katkoviiva kuvaa jakauman mediaania \(m_0 = 0.5\). Siniset alueet kuvaavat todennäköisyyksiä \(\mathbb{P}\left(X \leq m_0 - a\right)\) ja \(\mathbb{P}\left(X \geq m_0 + a\right)\). Kyseisen jakauman tapauksessa millä tahansa muulla \(a\):n valinnalla siniset pinta-alat ovat yhtäsuuria.
Olkoon \(\overrightarrow{X} = \{X_1, \ldots, X_n\}\) otos riippumattomia havaintoja satunnaismuuttujasta \(X\). Kaavan (5.1) hypoteeseja voidaan testata seuraavalla idealla. Kuten merkkitestissä, haluamme tarkastella sitä, kuinka moni havainto on pienempää kuin \(m_0\) tai suurempaa kuin \(m_0\). Tämän lisäksi otamme huomioon havaintojen etäisyyden arvosta \(m_0\) tietyllä tavalla. Tämän idean matemaattinen formalisointi johtaa merkkisijatestiin (eng: signed rank test). Määritellään satunnaismuuttujat \(Y_i = X_i - m_0\), \(i\in\{1, \ldots, n\}\) ja olkoon \(R(|Y_i|)\) satunnaismuuttujan \(|Y_i|\) sija (eng: rank). Esimerkiksi jos \(Y_1 = 2\), \(Y_2 = -3\) ja \(Y_3 = 0.5\), niin \(|Y_1| = 2\), \(|Y_2| = 3\) ja \(|Y_3| = 0.5\), jolloin \(R(|Y_3|) = 1\), \(R(|Y_1|) = 2\) ja \(R(|Y_2|) = 3\). Eli pienimmän itseisarvon sija on \(1\), toiseksi pienimmän itseisarvon sija on \(2\), …, suurimman itseisarvon sija on \(n\). Määritellään osoitinmuuttuja samaan tapaan kuin merkkitestissä, \[\begin{equation*} \mathrm{I}_i = \begin{cases} 1 & \text{jos}\ Y_i < 0, \\ 0, & \text{jos}\ Y_i \geq 0. \end{cases} \end{equation*}\] Toisin sanoen osoitinmuuttuja kertoo, onko havainto \(X_i\) pienempää kuin \(m_0\). Nyt merkkisijatestin testisuure on painotettu summa osoitinmuuttujista \[\begin{equation} \tag{5.3} T = \sum_{i = 1}^n R(|Y_i|)\mathrm{I}_i. \end{equation}\] Kuten merkkitestissä, tavallaan laskemme niiden havaintojen \(X_i\) määrän, jotka ovat pienempää kuin \(m_0\). Ero on siinä, että testisuureessa painotamme enemmän niitä havaintoja, jotka ovat kauempana arvosta \(m_0\).
Alla on esimerkki merkkisijatestin testisuureen laskemisesta.
Esimerkki 5.3 (Merkkisijatestin testisuure) Käytetään esimerkin 5.1 palkkadataa. Taulukon 5.2 ensimmäisessä sarakkeessa näkyy otos erään yrityksen työntekijöiden palkoista. Otoksen koko on \(n = 10\). Otoksen avulla haluamme testata, onko näyttöä sitä vastaan, että yrityksen työntekijöiden palkka on symmetrisesti jakautunut arvon \(m_0 = 3200\) ympärille. Taulukon avulla voimme laskea merkkisijatestin havaitun testisuureen arvon. Taulukosta näemme, että kahden työntekijän palkka on pienempi kuin \(m_0\) (työntekijöitä vastaavat rivit ollaan väritetty pinkillä). Näitä työntekijöitä vastaavien erotusten itseisarvojen sijat ovat \[\begin{equation*} R(|\texttt{salary}_1 - m_0|) = 2 \quad\text{ja}\quad R(|\texttt{salary}_6 - m_0|) = 6. \end{equation*}\] Havaitun testisuureen arvo on siis \(t = 2 + 6 = 8\). Merkkisijatestin nimi tuleekin siitä, että testisuuretta laskettaessa tarkastellaan erotuksien \(\texttt{salary}_i - m_0\) merkkejä (\(+\) tai \(-\)) ja sijoja.
| Palkka | \(\texttt{salary}_i - m_0\) | Erotuksen merkki | Erotuksen sija |
|---|---|---|---|
| 3000 | -200 | \(-\) | 2 |
| 5400 | 2200 | \(+\) | 7 |
| 3300 | 100 | \(+\) | 1 |
| 7300 | 4100 | \(+\) | 8 |
| 10000 | 6800 | \(+\) | 10 |
| 2600 | -600 | \(-\) | 6 |
| 3600 | 400 | \(+\) | 4 |
| 7600 | 4400 | \(+\) | 9 |
| 3700 | 500 | \(+\) | 5 |
| 3500 | 300 | \(+\) | 3 |
Voidaan laskea, että nollahypoteesin alla testisuureen odotusarvo ja varianssi ovat
\[\begin{equation*}
\mathbb{E}(T) = \frac{n(n+1)}{4} \quad\text{ja}\quad
\mathrm{Var}(T) = \frac{n(n + 1)(2n + 1)}{24}.
\end{equation*}\]
Suurella otoskoolla \((T - \mathbb{E}(T))/(\sqrt{\mathrm{Var}(T)})\) noudattaa likimain standardinormaalijakaumaa \(N(0,1)\) nollahypoteesin alla. Normaalijakauman avulla voidaan siis suorittaa likimääräinen merkkisijatesti. Kuitenkin R:n funktiolla wilcox.test() p-arvo voidaan laskea tarkasti, vaikka testisuureen tarkkaa jakaumaa ei voida ilmoittaa yksinkertaisella kaavalla.
Huomautus 5.2 Tässä luvussa käsiteltyyn merkkisijatestiin viitataan usein kirjallisuudessa nimellä Wilcoxonin merkkisijatesti kehittäjän sukunimen mukaan.
Esimerkki 5.4 (Merkkisijatestin p-arvo) Jatketaan esimerkkiä 5.3, jossa havaittu testisuure on \(t = 8\) ja otoskoko on \(n = 10\). Lasketaan ensin p-arvo normaaliapproksimaation avulla. Alla olevassa koodissa laskemme ensin suureen \(\tilde t = (t - \mathbb{E}(T))/(\sqrt{\mathrm{Var}(T)})\).
n <- 10
t <- 8
t_mean <- n * (n + 1)/ 4
t_var <- n * (n + 1) * (2 * n + 1)/ 24
t_tilde <- (t - t_mean) / sqrt(t_var)
t_tilde## [1] -1.987624Eli saamme \(\tilde t \approx -1.99\).
Olkoon \(\tilde T\) satunnaismuuttuja, joka noudattaa standardinormaalijakaumaa \(N(0,1)\) ja olkoon \(F\) jakauman kertymäfunktio. Standardinormaalijakauman symmetrisyyyden perusteella normaaliapproksimoitu p-arvo on \[\begin{equation*} \mathbb{P}\left(|\tilde T| \geq |\tilde t|\right) = \mathbb{P}\left(t \geq -\tilde t\right) + \mathbb{P}\left(t \leq \tilde t\right) = 2\mathbb{P}\left(t \leq \tilde t\right) = 2F(\tilde t), \end{equation*}\] Nyt voimme laskea normaaliapproksimoidun p-arvon R:n avulla.
## [1] 0.04685328Approksimoitu p-arvo voidaan laskea myös funktion wilcox.test() avulla. Jotta p-arvo lasketaan samoin kuin yllä, niin argumentit exact ja correct täytyy asettaa oikein. Alla olevassa koodissa vektori salary_data sisältää palkkadatan.
## [1] 3000 5400 3300 7300 10000 2600 3600 7600 3700 3500##
## Wilcoxon signed rank test
##
## data: salary_data
## V = 47, p-value = 0.04685
## alternative hypothesis: true location is not equal to 3200Argumentti correct vaikuttaa siihen, käytetäänkö jatkuvuuskorjausta normaaliapproksimaatiossa. Jos normaaliapproksimaatiota halutaan käyttää oikean elämän data-analyyseissä, niin yleensä kannattaa asettaa correct = TRUE. Tällöin kuitenkin saatu p-arvo ei vastaisi komennolla 2 * pnorm(t_tilde) “mekaanisesti” laskettua p-arvoa.
Huomioi, että funktio wilcox.test() raportoi erilaisen testisuureen kuin kaavassa (5.3) esitetty. Itseasiassa R raportoi testisuureen, joka lasketaan positiivisten erotuksien avulla. Eli R:n raportoima testisuure on \(7 + 1 + 8 + 10 + 4 + 9 + 5 + 3\) taulukon 5.2 mukaan. Sillä ei ole väliä määritelläänkö testisuure positiivisten vai negatiivisten erotuksien avulla.
Normaaliapproksimaatio on kätevä, jos työkaluina on vain paperi ja kynä. Kuitenkin nykyajan tietokoneilla tarkan p-arvon laskemisessa ei yleensä ole suurempia laskennallisia ongelmia.
##
## Wilcoxon signed rank exact test
##
## data: salary_data
## V = 47, p-value = 0.04883
## alternative hypothesis: true location is not equal to 3200Tarkka p-arvo eroaa hieman normaaliapproksimoidusta p-arvosta. Joka tapauksessa nollahypoteesi hylätään, kun käytetään merkitsevyystasoa \(\alpha = 0.05\). Meillä on siis näyttöä sitä vastaan, että palkkajakauma olisi symmetrinen arvon \(m_0 = 3200\) ympärillä.
Merkkisijatestillä voidaan myös vertailla kahden populaation samankaltaisuutta, jos havainnot ovat parittaisia. Oletetaan, että olemme havainneet kaksi otosta \(\overrightarrow{X} = \{X_1, \ldots, X_n\}\) ja \(\overrightarrow{Y} = \{Y_1, \ldots, Y_n\}\), joiden otoskoot ovat yhtäsuuret. Lisäksi oletetaan, että
Parin \((X_i, Y_i)^T\) sisällä saa olla riippuvuutta mutta
parit \(\{(X_1, Y_1)^T, (X_2, Y_2)^T, \ldots, (X_n, Y_n)^T\}\) ovat riippumattomia, ja
erotukset \(X_i - Y_i\) (tai \(Y_i - X_i\)) noudattavat jatkuvaa jakaumaa.
Tällöin erotuksien \(X_i - Y_i\) jakauman symmetrisyyttä nollan suhteen voidaan testata parittaisella merkkisijatestillä. Parittainen merkkisijatesti on vain yhden otoksen merkkitesti erotuksille \(X_i - Y_i\). Myös yksisuuntainen testi on mahdollinen aivan kuten t-testin ja merkkitestin tapauksessa.
Huomautus 5.3 (Merkkitestin ja merkkisijatestin oletuksista) Sekä merkki- että merkkisijatestissä ainoat oletukset ovat seuraavat.
Havainnot \(X_1, \ldots, X_n\) ovat riippumattomia ja samoin jakautuneita.
Havainnot \(X_1, \ldots, X_n\) noudattavat jatkuvaa jakaumaa.
Jakauman jatkuvuusoletus takaa seuraavat ominaisuudet.
Nollaerotuksen \(X_i - m_0 = 0\) todennäköisyys on nolla. Nollaerotukset ovat ongelmallisia siinä mielessä, että ne eivät ole \(+\)/\(-\) merkkisiä.
Merkkisijatestissä tapahtuman \(|Y_i| = |Y_j|\), \(i\neq j\), todennäköisyys on nolla. Tasahavainnot (eng: tie) \(|Y_i| = |Y_j|\) ovat ongelmallisia, koska tällöin havaintojen \(|Y_i|\) ja \(|Y_j|\) sija on sama.
Kuitenkin käytännön data-analyyseissa nollaerotukset ja tasahavainnot ovat mahdollisia. Esimerkiksi oletuksena funktio wilcox.test() pudottaa nollaerotukset analyysistä kokonaan pois ja tasahavainnoille annetaan sama keskisijaluku (eng: mid-rank). Keskisijaluku annetaan seuraavasti. Esimerkiksi, jos \(|Y_1| = 1\), \(|Y_2| = 4\) ja \(|Y_3| = 4\), niin \(R(|Y_1|) = 1\) ja \(R(|Y_2|) = R(|Y_3|) = (2 + 3) / 2 = 2.5\). Kuitenkin keskisijalukujen tapauksessa testisuureen tarkka jakauma nollahypoteesin alla on monimutkaisempi.
5.3 Sijasummatesti
Parittainen merkkitesti ja parittainen merkkisijatesti tarjoavat epäparametrisia työkaluja kahden populaation vertailuun, kun otokset ovat parittain riippuvia (katso oletukset tarkemmin luvun 5.1 tai luvun 5.2 lopusta). Tässä luvussa käsittelemme erästä epäparametrista testiä nimeltään sijasummatesti (eng: rank sum test) kahden populaation vertailuun, kun otokset ovat riippumattomia. Käsiteltävälle tilastolliselle testille käytetään kirjallisuudessa myös muita nimiä kuten Mann-Whitney testi tai Wilcoxonin testi.
Olkoon \(X\) satunnaismuuttuja, joka noudattaa jakaumaa \(F_X(x) = \mathbb{P}(X\leq x)\). Olkoon \(Y\) satunnaismuuttuja, joka noudattaa jakaumaa \(F_Y(y) = \mathbb{P}(Y\leq y)\). Sijasummatestissä testaamme seuraavaa nollahypoteesia \(H_0\) vaihtoehtoista hypoteesia \(H_1\) vastaan \[\begin{align*} &H_0: F_X = F_Y, \\ &H_1: F_X \neq F_Y. \end{align*}\] Olkoon \(\overrightarrow{X} = \{X_1, \ldots, X_n\}\) satunnaisotos satunnaismuutujasta \(X\) ja \(\overrightarrow{Y} = \{Y_1, \ldots, Y_m\}\) satunnaisotos satunnaismuutujasta \(Y\). Eli otoskoot voivat olla erisuuria \(n\neq m\). Sijasummatestissä oletamme, että
Yhdistetyn otoksen \(\overrightarrow{Z} = \{X_1, \ldots, X_n, Y_1, \ldots, Y_m\}\) havainnot ovat riippumattomia ja
jakaumat \(F_X\) ja \(F_Y\) ovat jatkuvia.
Oletus 2 takaa sen, että havaintoaineisto \(\overrightarrow{Z}\) ei sisällä tasahavaintoja. Nimensä mukaisesti sijasummatestin testisuureen laskemisessa käytetään yhdistetyn otoksen havaintojen sijoja, ja sijojen muodostaminen monimutkaistuu, jos data sisältää tasahavaintoja (katso huomautus 5.3).
Tarkemmin ottaen sijasummatestin testisuure lasketaan seuraavasti. Ensin muodostetaan yhdistetty otos \(\overrightarrow{Z}\). Tämän jälkeen lasketaan sija kaikille yhdistetyn otoksen havainnoille, niin että pienimmän havainnon sija on \(1\), toiseksi pienimmän havainnon sija on \(2\), …, suurimman havainnon sija on \(n + m\). Merkitään ensimmäisen otoksen \(\overrightarrow{X}\) havainnon \(X_i\), \(i\in\{1, \ldots, n\}\), sijaa notaatiolla \(R(X_i)\). Tällöin sijasummatestin testisuure on ensimmäisen otoksen sijojen summa \[\begin{equation} \tag{5.4} T = \sum_{i = 1}^n R(X_i). \end{equation}\] Testisuureen idea on se, että nollahypoteesin alla (satunnaismuuttujien \(X\) ja \(Y\) jakaumat ovat samoja), havaintoja \(X_i\) vastaavat sijat eivät ole systemaattisesti erilaisia verratuna havaintojen \(Y_i\) sijoihin. Esimerkiksi jos \(X_i\) arvot ovat systemaattisesti suurempia kuin \(Y_i\) arvot, niin meillä saattaa olla näyttöä nollahypoteesia vastaan.
Alla on esimerkki sijasummatestin testisuureen laskemisesta.
Esimerkki 5.5 (Sijasummatestin testisuure) Taulukon 5.3 toisessa sarakeessa näkyy yhdistetty otos kahden eri yrityksen työntekijöiden palkoista. Ensimmäisestä yrityksestä on \(n = 10\) kappaletta havaintoja \(\{x_1, \ldots, x_{10}\}\) ja toisesta yrityksestä on \(m = 7\) kappaletta havaintoja \(\{y_1, \ldots, y_{7}\}\). Haluamme testata, onko näyttöä siitä, että kahden eri yrityksen palkkajakaumat ovat erilaiset.
| ID | Palkka | Palkan sija |
|---|---|---|
| \(x_{1}\) | 3000 | 7 |
| \(x_{2}\) | 5400 | 14 |
| \(x_{3}\) | 3300 | 8 |
| \(x_{4}\) | 7300 | 15 |
| \(x_{5}\) | 10000 | 17 |
| \(x_{6}\) | 2600 | 5 |
| \(x_{7}\) | 3600 | 10 |
| \(x_{8}\) | 7600 | 16 |
| \(x_{9}\) | 3700 | 11 |
| \(x_{10}\) | 3500 | 9 |
| \(y_{1}\) | 2310 | 1 |
| \(y_{2}\) | 4130 | 13 |
| \(y_{3}\) | 2590 | 4 |
| \(y_{4}\) | 2680 | 6 |
| \(y_{5}\) | 2340 | 2 |
| \(y_{6}\) | 3900 | 12 |
| \(y_{7}\) | 2510 | 3 |
Havaittu testisuure on ensimmäisen otoksen \(\{x_1, \ldots, x_{10}\}\) havaintojen sijojen (väritetty pinkillä) summa eli \[\begin{equation*} t = \sum_{i = 1}^{10} R(x_i) = 112. \end{equation*}\] Taulukon viimeisen sarakkeen visuaalisen tarkastelun perusteella vaikuttaa siltä, että toista yritystä (\(y_i\)) vastaavat sijat ovat systemaattisesti pienempiä kuin ensimmäistä yritystä (\(x_i\)) vastaavat sijat. Kysymykseen onko tämä efekti tilastollisesti merkitsevä, vastaa p-arvo.
Voidaan laskea, että nollahypoteesin alla testisuureen odotusarvo ja varianssi ovat
\[\begin{equation*}
\mathbb{E}(T) = \frac{n(n + m + 1)}{2} \quad\text{ja}\quad
\mathrm{Var}(T) = \frac{nm(n + m + 1)}{12}.
\end{equation*}\]
Suurella otoskoolla \((T - \mathbb{E}(T))/(\sqrt{\mathrm{Var}(T)})\) noudattaa likimain standardinormaalijakaumaa \(N(0,1)\) nollahypoteesin alla. Normaalijakauman avulla voidaan siis suorittaa likimääräinen sijasummatesti. Kuitenkin R:n funktiolla wilcox.test() p-arvo voidaan laskea tarkasti, vaikka testisuureen tarkkaa jakaumaa ei voida ilmoittaa yksinkertaisella kaavalla. Eli antamalla argumentit eri tavoin, sekä merkkisijatesti että sijasummatesti voidaan suorittaa R:n funktiolla wilcox.test().
Esimerkki 5.6 (Sijasummatestin p-arvo) Jatketaan esimerkkiä 5.5, jossa havaittu testisuure on \(t = 112\), ensimmäisen otoksen koko on \(n = 10\) ja toisen otoksen koko on \(m = 7\). Lasketaan ensin p-arvo normaaliapproksimaation avulla. Alla olevassa koodissa laskemme ensin suureen \(\tilde t = (t - \mathbb{E}(T))/(\sqrt{\mathrm{Var}(T)})\).
n <- 10
m <- 7
t <- 112
t_mean <- n * (n + m + 1) / 2
t_var <- n * m * (n + m + 1) / 12
t_tilde <- (t - t_mean) / sqrt(t_var)
t_tilde## [1] 2.14698Samantyyppisellä perustelulla kuin esimerkissä 5.4 saamme laskettua normaaliapproksimoidun p-arvon seuraavasti.
## [1] 0.03179486Approksimoitu p-arvo voidaan laskea myös funktion wilcox.test() avulla. Jotta p-arvo lasketaan samoin kuin yllä, niin argumentit exact ja correct täytyy asettaa oikein. Alla olevassa koodissa vektori salary_data1 sisältää ensimmäisen yrityksen palkkadatan ja salary_data1 sisältää toisen yrityksen palkkadatan.
## [1] 3000 5400 3300 7300 10000 2600 3600 7600 3700 3500## [1] 2310 4130 2590 2680 2340 3900 2510wilcox.test(salary_data1, salary_data2, paired = FALSE,
alternative = "two.sided", exact = FALSE, correct = FALSE)##
## Wilcoxon rank sum test
##
## data: salary_data1 and salary_data2
## W = 57, p-value = 0.03179
## alternative hypothesis: true location shift is not equal to 0Huomaa, että R raportoi itseasiassa keskitetyn testisuureen \(W = T - \frac{n(n+1)}{2}\) eikä kaavan (5.4) testisuuretta. Kuitenkin molemmat \(W\) ja \(T\) sisältävät saman informaation – testisuureen \(W\) jakauma on vain hieman kivempi.
Tarkka p-arvo testisuureen \(W\) tarkasta jakaumasta lasketaan alla.
##
## Wilcoxon rank sum exact test
##
## data: salary_data1 and salary_data2
## W = 57, p-value = 0.03301
## alternative hypothesis: true location shift is not equal to 0Normaaliapproksimoitu ja tarkka p-arvo ovat melko lähellä toisiaan. Joka tapauksessa nollahypoteesi hylätään, kun käytetään merkitsevyystasoa \(\alpha = 0.05\). Meillä on siis näyttöä sen puolesta, että kahden yrityksen palkkajakaumat olisivat erilaiset.
5.4 Kruskal–Wallis testi
Merkkitesti ja merkkisijatesti antavat epäparametriset vaihtoehdot yhden otoksen t-testille (ja parittaiselle t-testille). Toisaalta sijasummatesti antaa epäparametrisen vaihtoehdon kahden otoksen t-testille. Viimeiseksi Kruskal–Wallis testi on epäparametrinen versio ANOVA:sta (katso luku 4.3).
Olkoon \(X_1, X_2, \ldots, X_d\) satunnaismuuttujia, joista kukin noudattaa jakaumaa \(F_j\), \(j\in\{1,2, \ldots, d\}\). Kruskal–Wallis testissä testaamme seuraavaa nollahypoteesia \(H_0\) vaihtoehtoista hypoteesia \(H_1\) vastaan \[\begin{align*} &H_0: F_1 = F_2 = \cdots = F_d, \\ &H_1: F_j \neq F_k \quad\text{jollekin}\quad j,k\in\{1,2, \ldots, d\}. \end{align*}\] Olkoon \(\overrightarrow{X}_j = \{X_{1j}, \ldots, X_{n_jj}\}\) satunnaisotos satunnaismuutujasta \(X_j\). Eli otoskoot \(n_j\) voivat olla erisuuria. Kruskal–Wallis testissä oletamme, että
Yhdistetyn otoksen \(\overrightarrow{Z} = \overrightarrow{X}_1 \cup \overrightarrow{X}_2 \cup \cdots \cup \overrightarrow{X}_d\) havainnot ovat riippumattomia ja
jakaumat \(F_j\) ovat jatkuvia.
Oletus 2 takaa sen, että havaintoaineisto \(\overrightarrow{Z}\) ei sisällä tasahavaintoja16. Kuten sijasummatestissä myös Kruskal–Wallis testin testisuure liittyy ryhmien havaintojen \(\overrightarrow{X}_j\) sijojen summiin. Ensin lasketaan yhdistetyn otoksen \(\overrightarrow{Z}\) havaintoja vastaavat sijat \(R(X_{ij})\). Tämän jälkeen jokaiselle ryhmälle \(j\in\{1,2, \ldots, d\}\) lasketaan sijojen summa \[\begin{equation*} S_j = \sum_{i = 1}^{n_j} R(X_{ij}). \end{equation*}\] Testisuureen \(T\) ideana on vertailla eri ryhmiä vastaavia sijojen summia \(S_j\) \[\begin{equation*} T = \sum_{j = 1}^d \frac{S_j^2}{n_j}. \end{equation*}\] Olkoon \(n = \sum_{j = 1}^j n_j\) yhdistetyn otoksen otoskoko. Testisuureen \(T\) jakauma on monimutkainen nollahypoteesin alla mutta muokattu testisuure \[\begin{equation} \tag{5.5} \tilde T = \frac{12}{n(n + 1)} T - 3(n + 1) \end{equation}\] noudattaa likimain khi-neliöjakaumaa \(\chi^2_{d-1}\) vapausasteella \(d - 1\) nollahypoteesin alla. Tällöin p-arvo saadaan approksimoitua todennäköisyydellä \(\mathbb{P}\left(\tilde T\geq \tilde t\right)\). jossa \(\tilde t\) on kaavan (5.5) mukainen havaittu testisuure. Kuva 5.4 havainnolistaa p-arvon laskemista khi-neliöjakaumasta.
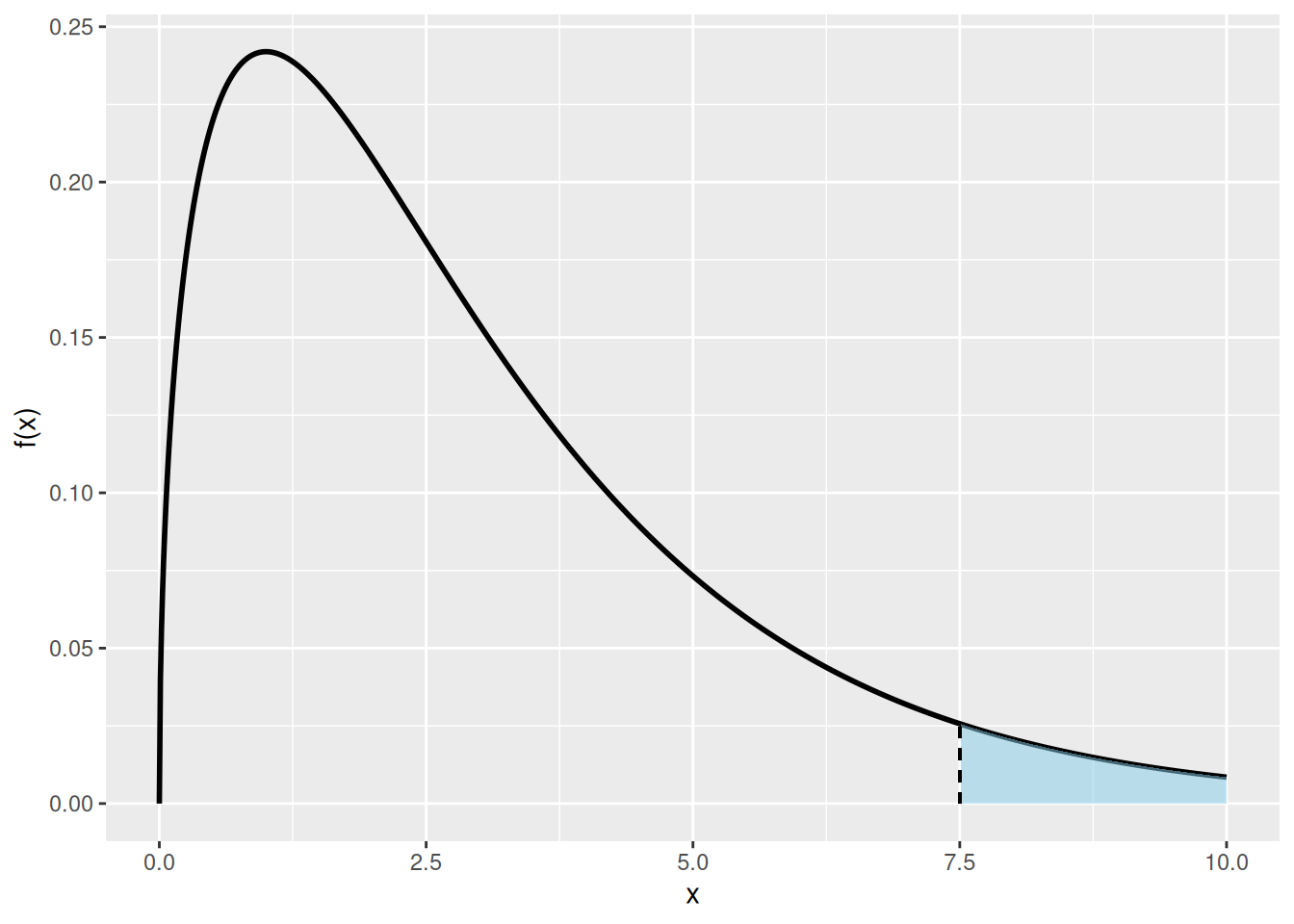
Kuva 5.4: Kiinteä musta käyrä kuvaa khi-neliöjakauman \(\chi_3^2\) tiheysfunktiota. Tässä tapauksessa vapausaste on \(3\), joten vertailtavia populaatioita on \(4\) kappaletta. Katkoviiva kuvaa havaitun testisuureen \(\tilde t\) arvoa. Jos havaituksi testisuureeksi saadaan \(\tilde t = 7.5\), niin sininen pinta-ala kuvaa p-arvoa.
Kruskal–Wallis testi voidaan suorittaa R:ssä funktiolla kruskal.test(). Testin p-arvon laskeminen testisuureen tarkan jakauman avulla on laskennallisesti vaativaa suurella otoskoolla, joten funktio kruskal.test() käyttää khi-neliöjakaumaa p-arvon laskemiseen. Alla olevassa esimerkissä suoritamme Kruskal–Wallis testin ensin funktiolla kruskal.test() ja sitten “manuaalisesti”.
Esimerkki 5.7 (Kruskal-Wallis testin suorittaminen) Suoritetaan esimerkin 4.8 analyysi Kruskal–Wallis testin avulla ANOVA:n sijasta. Meillä on siis \(n = 20\) kokoiset otokset neljästä tehtaasta. Otokset sisältävät tuotettujen suklaalevyjen painoja jokaisesta tehtaasta. Alla näkyy kaikkia neljää tehdasta vastaavat otokset suklaalevyistä.
## # A tibble: 20 × 4
## factory1 factory2 factory3 factory4
## <dbl> <dbl> <dbl> <dbl>
## 1 103. 102. 101. 89.5
## 2 98.3 111. 110. 91.8
## 3 111. 102. 103. 82.8
## 4 101. 93.7 110. 78.0
## 5 107. 104. 97.2 98.3
## 6 102. 101. 95.6 89.5
## 7 107. 91.2 93.9 92.4
## 8 101. 87.8 88.4 83.5
## 9 97.8 93.7 102. 99.6
## 10 107. 95.6 108. 96.0
## 11 93.4 100.0 102. 92.3
## 12 103. 105. 105. 86.6
## 13 91.8 97.7 97.9 82.7
## 14 88.9 96.8 96.7 81.8
## 15 97.4 98.4 101. 81.5
## 16 98.8 96.4 98.2 88.5
## 17 108. 98.0 95.0 82.6
## 18 101. 98.6 105. 91.3
## 19 99.3 94.8 109. 90.4
## 20 104. 94.9 104. 95.1Haluamme siis tutkia, onko jossain tehtaassa suklaalevyjen keskimääräinen paino poikkeava verrattuna muihin tehtaisiin? Suoritetaan Kruskal–Wallis testi käyttäen merkitsevyystasoa \(\alpha = 0.05\).
Muokataan data siten, että sen voi syöttää helposti funktioon kruskal.test(). Muutamme datan siis sellaiseen muotoon, jossa ensimmäinen sarake kertoo suklaalevyn tuotantosijainnin ja toinen sarake levyä vastaavan painon.
library(tidyr)
choco_mod <- choco %>%
pivot_longer(everything(), names_to = "factory", values_to = "weight") %>%
mutate(factory = factor(factory))
choco_mod## # A tibble: 80 × 2
## factory weight
## <fct> <dbl>
## 1 factory1 103.
## 2 factory2 102.
## 3 factory3 101.
## 4 factory4 89.5
## 5 factory1 98.3
## 6 factory2 111.
## 7 factory3 110.
## 8 factory4 91.8
## 9 factory1 111.
## 10 factory2 102.
## # ℹ 70 more rowsNyt voimme suorittaa Kruskal–Wallis testin.
##
## Kruskal-Wallis rank sum test
##
## data: weight by factory
## Kruskal-Wallis chi-squared = 32.714, df = 3, p-value = 3.701e-07Testin antama p-arvo on selkeästi pienempää kuin asetettu merkitsevyystaso. Meillä on siis näyttöä sen puolesta, että ainakin yhdessä tehtaassa suklaanlevyjen painojen jakauma on erilainen kuin muissa tehtaissa.
Voimme myös suorittaa testin käsin. Tätä varten laskemme ensin tehtaita vastaavien sijojen summat \(S_i\).
rank_sums <- choco_mod %>%
mutate(rank = rank(weight)) %>%
group_by(factory) %>%
summarise(rank_sum = sum(rank))
rank_sums## # A tibble: 4 × 2
## factory rank_sum
## <fct> <dbl>
## 1 factory1 1051
## 2 factory2 828
## 3 factory3 1042
## 4 factory4 319Nyt voimme laskea testisuureen (\(t\) tai \(\tilde t\)).
n <- nrow(choco_mod)
ni <- table(choco_mod$factory)
t <- sum(rank_sums$rank_sum^2 / ni)
t_tilde <- 12 / (n * (n+1)) * t - 3 * (n + 1)
t_tilde## [1] 32.71389Tehtaita on yhteensä \(d = 4\) kappaletta, joten testisuure noudattaa likimain khi-neliöjakaumaa vapausasteella \(k - 1 = 3\). Nyt voimme laskea p-arvon käsin. Saamme saman p-arvon kuin funktiota kruskal.test() käyttäen.
## [1] 3.70075e-07Lähteet
Painotamme vielä tässä kohtaa, että kaikkia luvun testejä (merkkitesti, merkkisijatesti, sijasummatesti ja Kruskal–Wallis testi) käytetään myös diskreeteille havaintoaineistoille. Kaikista testeistä on olemassa versioita, jotka toimivat esimerkiksi tasahavaintojen tapauksissa.↩︎